Almost all people who play reptiles will definitely use the requests library. The author of this library is the famous Kenneth Reitz. In a mess, I recently browsed its website and found that he had a new move. A library that combines a reptile downloader and a parser is a great boon to the reptile community. Let's learn it together.

01
Requests-Html
This library is a companion to the requests library. Generally speaking, we will crawl the web. After downloading the webpage, I will install some parsing libraries to parse web pages. There are many kinds of parsing libraries, which increases our learning costs.
Is there a library that fuses the two together and provides it to us conveniently. However, this library has a built-in html web page parser, which is equivalent to bring your own drinks and is very convenient. It is known as a web parsing library for humans.
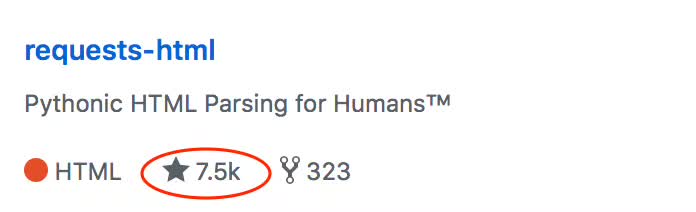
At present, this library has already harvested 7,500 likes, 323fork, quite awesome!
02
This library has a
We only need to use pip direct install. Pip install requests-html, which has built-in the requests library, pyquery library, bs library, and some coded libraries. The best part is that it actually integrates the random agent library fake-useragent!
# what packages are required for this module to be executed?

What are the built-in features:
Full JavaScript support!
CSS Selectors (aka jQuery-style, thanks to PyQuery).
XPath Selectors, for the faint at heart.
Mocked user-agent (like a real web browser).
Automatic following of redirects.
Connection–pooling and cookie persistence.
The Requests experience you know and love, with magical parsing abilities.
03
How to use this library
1). For example, we crawl a Python website
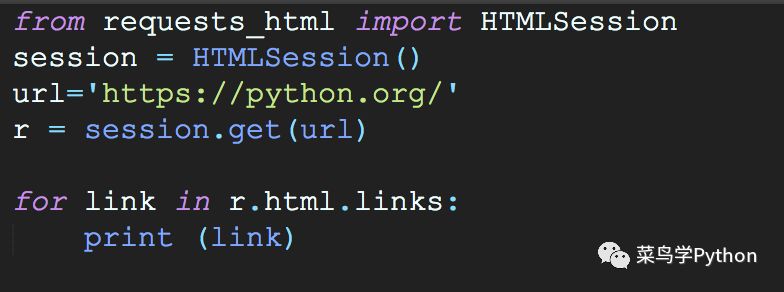
>>/about/quotes//about/success/#software-developmenthttps://mail.python.org/mailman/listinfo/python-dev/downloads/release/python-365//community/logos//community/sigs ///jobs.python.orghttp://tornadoweb.orghttps://github.com/python/pythondotorg/issues/about/gettingstarted/...
Simple, we do not need to control what the http request header, do not need to manage what cookie, but also do not need to manage the entity angent. Directly initialize an HTMLSession () class object, you can simply parse the content of the page. While drinking a cup of tea, you can directly call methods inside the r object, such as extracting hyperlinks from all web pages.
2). Look at the good methods in the HTMLSession object:
Print ([e for e in dir(r.html) if not e.startswith('_')])>>['absolute_links', 'add_next_symbol', 'base_url', 'default_encoding', 'element', 'encoding ', 'find', 'full_text', 'html', 'links', 'lxml', 'next_symbol', 'page', 'pq', 'raw_html', 'render', 'search', 'search_all', 'session', 'skip_anchors', 'text', 'url', 'xpath']
There are many useful function functions, such as find, search, search_all function, very convenient! Above we have parsed the Python official website, and then we analyze about the official website:
Want to find the content of the text in the about element, we can only get one line of code to find out
About = r.html.find('#about', first=True)print (about.text)>>About Applications Quotes Getting Started Help Python Brochure
#about is to indicate that the id of the web page review is about (css mode extraction). If first element is a list, we only return the first element.
Want to read the attr inside about:
Print (about.attrs)>>{'id': 'about', 'class': ('tier-1', 'element-1'), 'aria-haspopup': 'true'}
Want to read the link inside about:
About.find('a')>>
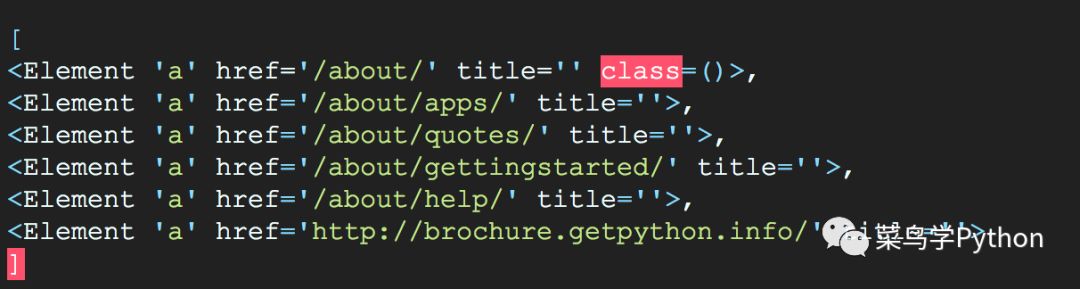
The most astounding is that this About object has initialized the object handles of various parsing libraries, such as the parsing of the famous pyquery library (css parser) and the parsing of the lxml library.
Directly using doc=about.pq, the doc here is actually parsing the contents of the css parsing, we can very convenient processing.
The entire requests_html library is equivalent to a middle tier. The complex steps of parsing web pages are once again encapsulated. There are also powerful features, such as support for dynamic parsing of js pages, built-in powerful chroma engine, and asynchronous Parse the session (AsyncHTMLSession), which uses Python's Asyncio library.
In short, with this requests_html, my mother no longer has to worry about learning to crawl.
Power X (Qingdao) Energy Technology Co., Ltd. , https://www.solarpowerxx.com