The theme shared with you today is Knowledge Mapping and Cognitive Intelligence.
Since it was proposed in 2012, Knowledge Map has developed rapidly. Now it has become one of the hot issues in the field of artificial intelligence, attracting a lot of attention from academia and industry, and achieving a better landing effect in a series of practical applications. Great social and economic benefits. What exactly is it supporting the prosperity of knowledge mapping technology? Is it a force that draws knowledge mapping technology so much attention? In other words, what exactly does Knowledge Mapping solve? How can we solve these problems? Today's report mainly revolves around these issues and gives you a preliminary answer.
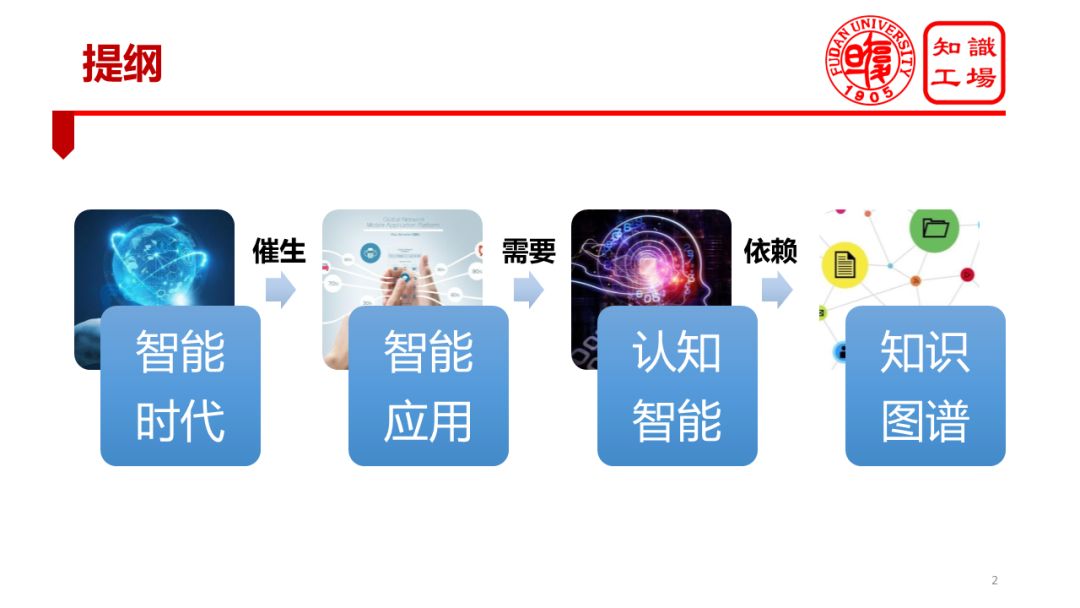
Briefly introduce the overall idea of ​​the entire report. Human society has entered the era of intelligence. The social development in the intelligent era has spawned a large number of intelligent applications. Intelligent applications have brought unprecedented demands on the level of cognitive intelligence of machines. The realization of machine cognitive intelligence relies on knowledge mapping technology.
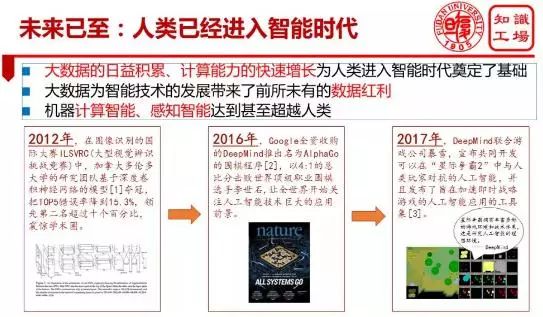
I think we have deeply felt that we are living in an intelligent era.
Since 2012, Google’s image recognition error rate has dropped significantly, and the machine has approached humans in image recognition; by 2016 AlphaGo defeated the human Go Championship; by 2017 AlphaZero defeated AlphaGo, and DeepMind went to try the StarCraft game. The iconic events of the series AI development let us see the hope of artificial intelligence technology helping solve the problems of human society development. The development of this series of artificial intelligence technologies that we have witnessed is essentially benefiting from the data dividend brought by big data to artificial intelligence.
This wave of artificial intelligence has been formed under the powerful support of massive data samples given by Big Data and powerful computing capabilities. It can be said that the development of this wave of artificial intelligence is essentially feeding out of big data. Today, it can be proud to announce that machine intelligence has reached or even surpassed human level on several specific issues such as perceived intelligence and computational intelligence. Nowadays, on the issues of speech recognition and synthesis, image recognition, and the limited rules of the enclosed game field, the level of machine intelligence is comparable to, or even exceeds, human standards.
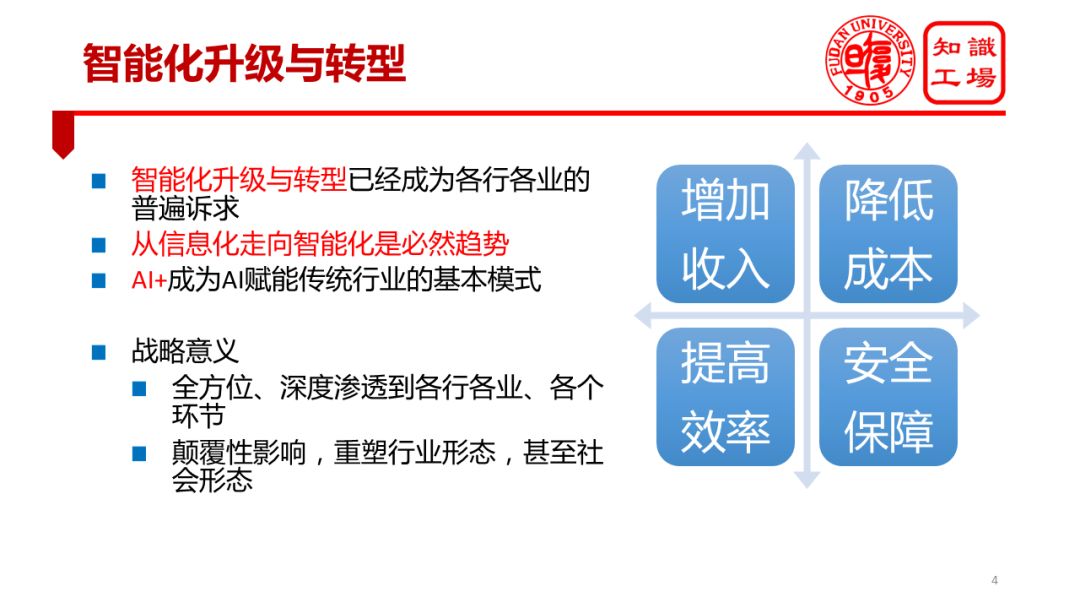
This series of breakthroughs in artificial intelligence technology has prompted all walks of life to move toward an intelligent upgrade and transformation path. Intelligent technology has brought new opportunities for the development of traditional industries in China, which has brought new opportunities for the upgrading of China’s economic structure and the divergence of traditional physical industries from the current series of development difficulties. Intelligent upgrades and transformation have become the common aspirations of all walks of life. The development of intelligent industries in various industries is, in a sense, an inevitable trend in the development of human society.
Since the advent of computers, human society has basically completed the informationization mission after experiencing a series of wave of computer technology development. The most important task in the information age is data recording and collection, which is bound to create big data. When we step into the era of big data, we are bound to appeal for the value of big data mining. The value mining of big data requires intelligent means. Therefore, the arrival of the era of big data, in a sense, is only a brief overture of the intelligent era. I believe that in the coming years, the main mission of computer technology is to help human society achieve intelligence.
In the intelligent development process of various industries, AI+ or AI empowerment has become a basic model for intelligent upgrading and transformation of traditional industries. With the creation of AI, traditional industries are faced with many opportunities. A series of core issues that they care about, such as increasing revenue, reducing costs, improving efficiency, and ensuring security, will all benefit significantly from intelligent technologies. For example, the smart customer service system has been applied in a large scale in many industries, greatly reducing the labor cost of artificial customer service. Some companies use knowledge maps to manage internal R&D resources and significantly improve R&D efficiency. These are AIs that can empower traditions. The specific embodiment of the industry.
The impact of intelligent upgrades and transformations on the entire traditional industry will be disruptive. It will reshape the entire industry and innovate key links in traditional industries. Intelligent technologies will gradually penetrate into every corner of traditional industries. In recent years we have seen more and more traditional industries upgrade the field of artificial intelligence into the company's core strategy. More and more AI have emerged in many fields such as e-commerce, social networking, logistics, finance, medical care, justice, and manufacturing. Enabling the development of traditional industries.
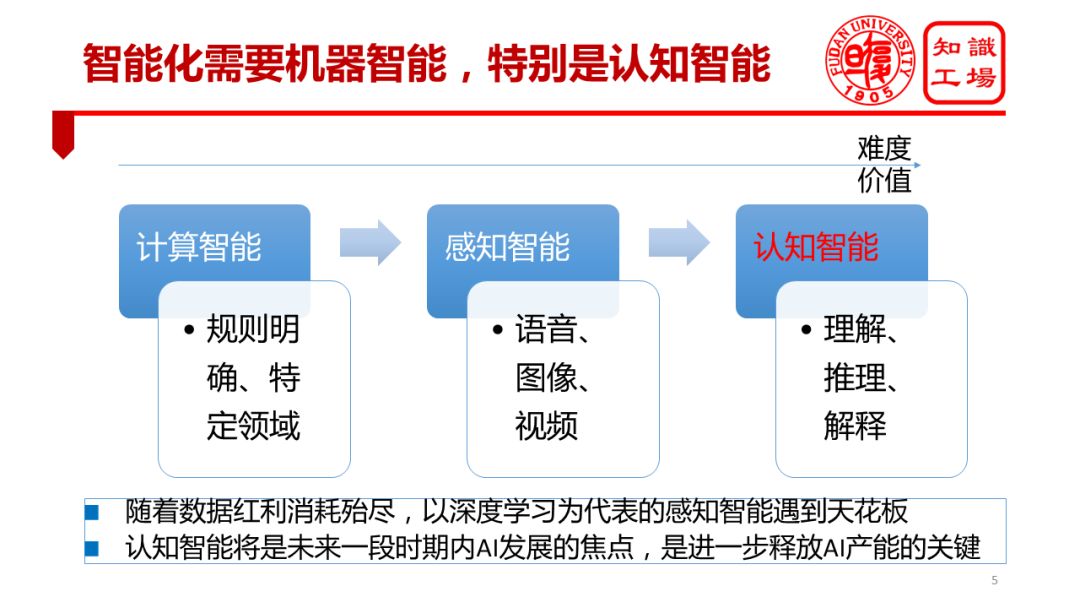
Intelligence puts forward requirements on the intelligent level of the machine, including the computational intelligence and perceived intelligence of the machine, especially the cognitive intelligence of the machine. The so-called "cognitive intelligence" refers to the machine's ability to think like a person. This thinking ability is embodied in the machine's ability to understand data, understand the language, and understand the real world. It is reflected in the machine's ability to interpret data, explain the process, and explain The power of phenomena is reflected in a series of human cognitive powers, such as reasoning and planning.
Compared with cognitive ability, cognitive ability is more difficult to achieve and worth more. In the past few years, under the impetus of deep learning, machine awareness has improved significantly. However, the ability to sense animals is also available, such as our family's kittens can recognize the owner, identify objects. Therefore, letting machines have the ability to perceive only allows the machine to possess the capabilities of ordinary animals, and it is not so worthwhile to show off. However, cognitive ability is unique to human beings. Once machines have cognitive abilities, AI technology will revolutionize human society and release huge industrial energy. Therefore, the realization of the machine's cognitive ability is a milestone event in the development process of artificial intelligence.
With the disappearance of big data dividends, the level of perceived intelligence represented by deep learning is increasingly approaching its “ceilingâ€. Statistical learning represented by deep learning relies heavily on large samples. These methods can only acquire statistical patterns in data. However, the solution to many practical problems in the real world alone is not enough to rely on statistical models. It also requires knowledge, especially symbolic knowledge.
Many areas of our human language understanding, judicial decisions, medical diagnoses, investment decisions, etc. are significantly dependent on our knowledge to achieve. Many R&D personnel engaged in natural language processing generally have a profound feeling: Even if the data volume is large, the model is advanced, and many natural language processing tasks, such as Chinese word segmentation and sentiment analysis, reach a certain accuracy rate, it is difficult to improve.
For example, a classic case of Chinese word segmentation: "Nanjing Yangtze River Bridge", whether it is divided into "Nanjing Mayor + River Bridge" or "Nanjing + Yangtze River Bridge" relies on our knowledge. If we learn from the context that we are discussing the Mayor of Nanjing and there is a person named Jiang Bridge, we will tend to divide it into the "Nanjing Mayor + Jiang Bridge", otherwise we will use the knowledge we already have to say "Nanjing City + Yangtze River Bridge." In either case, we are using our knowledge. I remember academician Xu Zongben, a well-known statistician in China, said at a forum at the end of last year: "The data is not enough for model compensation." I would like to convey a similar point of view: "The data is not enough knowledge to supplement", or even "the data is enough, knowledge can not be lost." The knowledge map is one of the important manifestations of this indispensable knowledge.
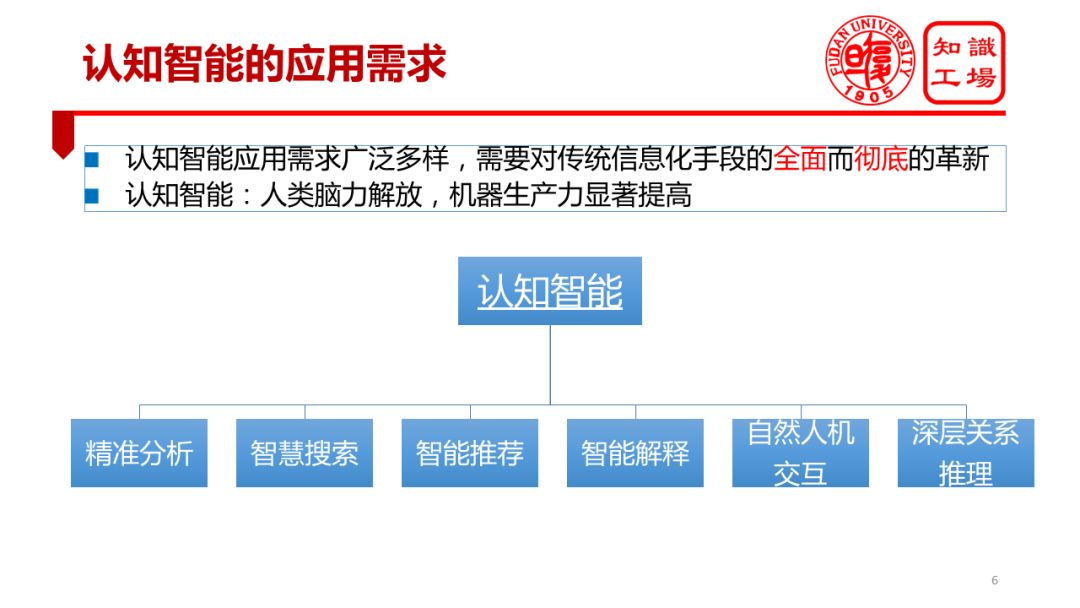
Machine cognitive intelligence is by no means a cutting-edge technology. It is a type of technology that can actually land on the ground, has a wide range of diverse application requirements, and can generate great social and economic value. The development process of machine cognitive intelligence is essentially the process of the constant liberation of the human brain. In the era of industrial revolution and informatization, our physical strength was gradually liberated; and with the development of artificial intelligence technology, especially the development of cognitive intelligence technology, our brain power will gradually be liberated. More and more knowledge work will be gradually replaced by machines, which will be accompanied by further liberation of machine productivity. Machine cognitive intelligence is widely and diversely applied in various aspects such as precision analysis, intelligent search, smart recommendation, intelligent interpretation, more natural human-computer interaction, and deep relationship reasoning.

The first application of cognitive intelligence is the precision and refinement of big data. Today, more and more industries or companies have accumulated large-scale big data. However, these data do not play its due value. Many big data also need to consume a lot of operation and maintenance costs. Big data not only does not create value, but in many cases it also becomes a negative asset. The root cause of this phenomenon is that current machines lack background knowledge such as knowledge maps. Machines have limited means to understand big data, limiting the precision and fine-grained analysis of big data, thereby greatly reducing the potential value of big data.
To give an example of personal experience, at the beginning of the divorce case in the entertainment industry, Wang Baoqiang, Sina Weibo’s top three hot searches were “Wang Baoqiang's divorce,†“Baby's divorce,†and “Baoqiang divorce.†In other words, the Weibo platform at that time was not yet able to automatically classify these three things into one thing. It is not known that these three things are actually one thing. When the statistics of the events were hot, the machines separated their statistics. This was because the machines lacked background knowledge and Wang Baoqiang was also known as “Baby Baby†or “Baqiangâ€. Therefore, there is no way to accurately analyze big data.
In fact, public opinion analysis, commercial insight on the Internet, and military intelligence analysis and business intelligence analysis all require accurate analysis of big data. This kind of precise analysis must have strong background knowledge. In addition to the precise analysis of big data, another important trend in the field of data analysis is fine analysis, and it also raises the demand for knowledge mapping and cognitive intelligence. For example, many car manufacturers want to achieve personalized manufacturing. Personalized manufacturing hopes to collect user's evaluation and feedback from the Internet, and use this as a basis to realize the on-demand and personalized customization of automobiles. In order to achieve customization, manufacturers need to not only understand the consumer's attitude towards car criticism, but also need to further understand the details of consumer dissatisfaction, and how consumers want to improve, and even what competing brands the user refers to. Obviously, the refined data analysis for Internet data must require the machine to have background knowledge about car evaluation (such as car models, trim, power, energy consumption, etc.). Therefore, the precision and refinement analysis of big data requires intelligent technical support.

The second very important application of cognitive intelligence is smart search. The next generation of smart search puts demands on machine cognitive intelligence. Smart search is reflected in many ways.
First, it is reflected in the precise understanding of search intentions. For example, on the Taobao search for "iPad charger", the user's intention is obviously to search for a charger, rather than an iPad, this time Taobao should give users a number of chargers to choose from, rather than the iPad. Another example is Google search for "toys kids" or "kids toys". Regardless of which of the two is searched, the user's intention is to search for toys for children instead of children for toys, because generally there will be no one. Search for children with search engines. Both words "toys kids" and "kid's toys" are nouns. To identify which one is the core word and which one is the modifier, it is still a challenging problem in the absence of contextual short text.
Second, the search targets are becoming more and more complex and diverse. Previously searched for text-based objects, and now everyone hopes to search for pictures and sounds, and even search for code, search for videos, search for design materials, etc., require everything to be searchable.
Third, the granularity of search has become more diversified. The current search can not only do chapter-level search, but also hopes to be able to do paragraph-level, statement-level, vocabulary-level search. Especially in the field of traditional knowledge management, this trend has become very clear. Most of the traditional knowledge management can only achieve document-level search. This kind of coarse-grained knowledge management has been difficult to meet the fine-grained knowledge acquisition requirements in practical applications.
Finally, cross-media collaborative search. Traditional search is mostly searched for single-source, single-source data. For example, for text search, it is difficult to leverage video and picture information. The search for pictures mainly uses the information of the picture itself, and the utilization rate of a large amount of text information is not high. The most recent trend is cross-media collaborative search. For example, in the past few years, the star Wang Haodan has photographed Zhang's own community on Weibo, and then there are good media based on her Weibo social network, Baidu maps, Weibo text and picture information and other channels. Accurately infer the location of the cell where it is located through the joint search. So, the trend in the future is that everything can be searched, and search will be necessary.
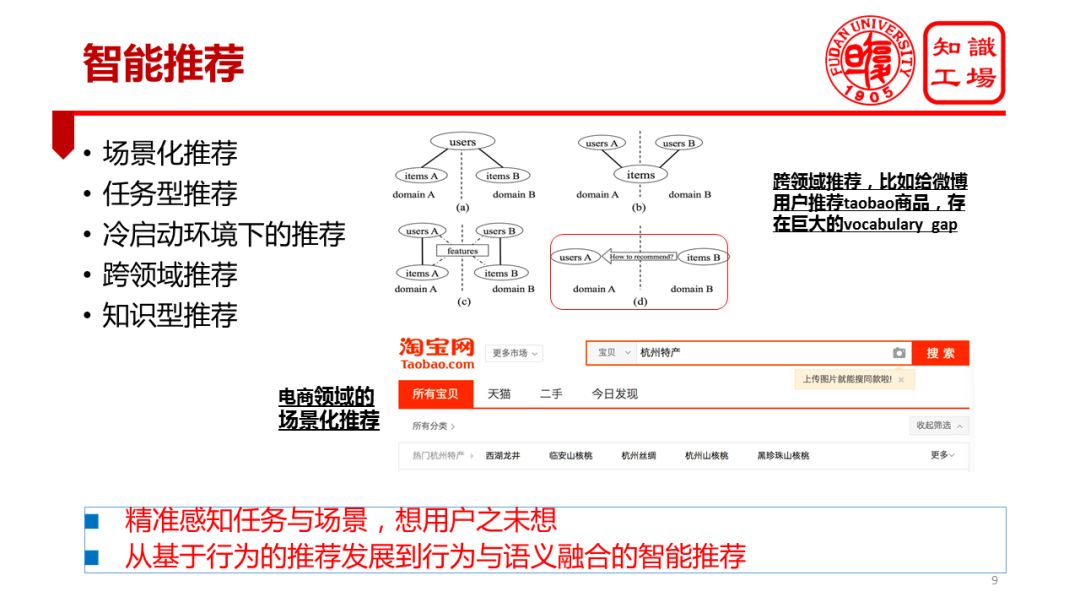
The third application of cognitive intelligence is smart recommendation. Smart recommendations are performed in many ways.
The first is the scene recommendation. For example, if a user searches for “beach pants†or “beach shoes†on Taobao, it is speculated that the user is likely to go to the beach for a vacation. So can the platform recommend "swimwear", "sunscreen" and other beach resort items? In fact, behind any search keyword, there is a specific consumer intent behind any product in the shopping basket, which is likely to correspond to a specific consumption scenario. Establishing scene graphs to achieve accurate recommendation based on scene graphs is crucial for e-commerce recommendations.
Second, task-type recommendations. The motivation behind many searches is to accomplish specific tasks. For example, if the user purchases "mutton roll", "beef roll", "spinach", "hot pot bottom material", then the user is likely to do a hot pot, in this case, the system recommends hot pot seasoning, hot pot cooker, user It is very likely to pay.
Third, the recommendation of cold start. The recommendation of the cold start phase has always been a problem that is difficult to effectively solve by traditional recommendation methods based on statistical behavior. The use of external knowledge, especially the matching and recommendation of the user and the article's knowledge guidelines during the cold start phase, is likely to allow the system to get through this stage as soon as possible. Fourth, cross-domain recommendations.
When Ali had just joined Sina, we were wondering if we could recommend Taobao's products to Weibo users. For example, if a Weibo user regularly photographs Jiuzhaigou, Huangshan, and Taishan, then recommend this user to some of Taobao's climbing equipment. This is a typical cross-domain recommendation. Weibo is a media platform. Taobao is an e-commerce platform. Their language system and user behavior are completely different. Realizing this cross-domain recommendation is obviously of great commercial value, but it needs to span a huge semantic gap.
If this background knowledge such as the knowledge map can be used effectively, this semantic gap between different platforms may be crossed. For example, the encyclopedic knowledge map tells us that Jiuzhaigou is a scenic spot. It is a mountainous area. Mountainous areas need mountaineering equipment. Mountaineering equipment includes trekking poles, hiking shoes, etc., so that cross-domain recommendations can be achieved. Fifth, knowledge-based content recommendation. When searching for “three-stage milk powder†on Taobao, can you recommend the “baby water cup†and at the same time, can we recommend the user how much the daily water requirement for the baby who drinks the three-stage milk powder, and how to drink it? The recommendation of these knowledge will significantly enhance the user's trust and acceptance of the recommended content. The content and knowledge requirements behind consumption will become an important consideration for recommendations.
Therefore, the future recommendation trend is to accurately perceive tasks and scenarios and think of users. The important trends in recommending technology evolution are the transition from simply behavior-based recommendations to recommendations where behavior and semantics converge. In other words, recommendation based on knowledge will gradually become the mainstream of recommended technologies in the future.
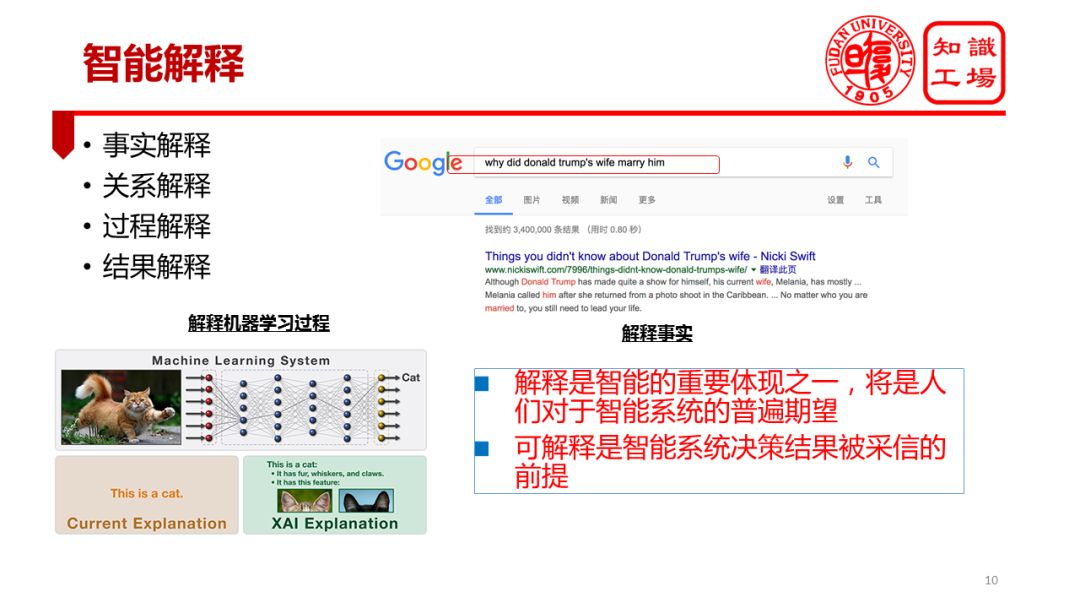
The fourth application of cognitive intelligence is intelligent interpretation. At the end of 2017, Wechat circulated the most popular search keyword in Google's 17 years as "how", which shows that people hope that the Google platform can do "interpretation." Similar to "how to make egg fried rice," "how to come to North Polytechnic," and other issues such as the emergence of a growing number of search engines, these problems are testing the level of interpretation of the machine. An even more interesting example is when we search Google for "Donald Trump" related issues, you will find that Google automatically prompts "Why Trump's wife married him" instead of "Trump wife" Who is this kind of simple facts? The "why" and "how" issues are increasingly used in real-world applications. This trend actually embodies one of the people’s general aspirations, and that is the hope that intelligent systems are interpretable. So interpretability will be a very important manifestation of intelligent systems, and it is also people's general expectations for intelligent systems.
Explainability determines whether the AI ​​system's decision results can be used by humans. Explainability has become the last mile in many fields (financial, medical, judicial, etc.) that impede the application of AI systems. For example, in the intelligent investment decision-making in the financial field, even if the accuracy of the AI ​​decision exceeds 90%, but if the system can not give reasons for making a decision, the investment manager or user may also be very hesitant. For example, in the medical field, even if the system determines that the accuracy of the disease is above 95%, if the system only tells the patient what the disease is or has prescribed a prescription, it cannot explain why such judgments are made. Paying.
The interpretability of intelligent systems is reflected in many specific tasks, including the process of interpreting, interpreting results, interpreting relationships, and interpreting facts. In fact, interpretable artificial intelligence has recently received more and more attention. In academia, the black box feature of machine learning, especially deep learning, has increasingly become one of the major obstacles to the practical application of learning models. The more academic research projects are aimed at opening deep learning black boxes. The U.S. military also has projects trying to explain the machine learning process. Personally, I have also done research and reflection on “Analyzing Artificial Intelligence Based on Knowledge Atlas†to emphasize the important role of the knowledge map in interpretability.
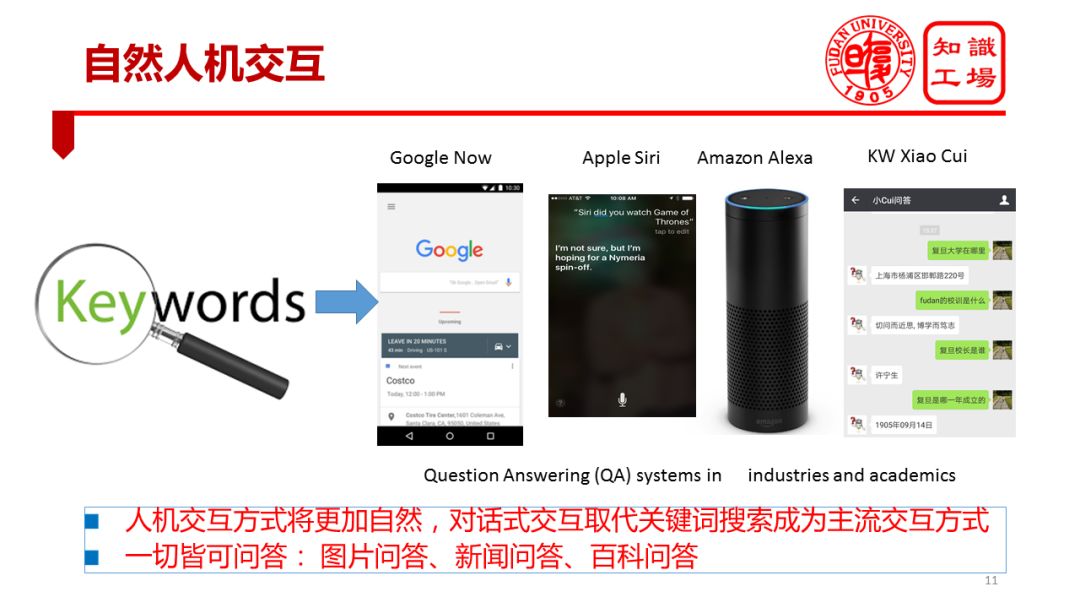
Another very important manifestation of intelligent systems is natural human-computer interaction. Human-computer interaction will become more natural and simpler. The more natural and simple the interactive mode, the more it depends on the level of powerful machine intelligence. Natural human-computer interaction includes natural language questions and answers, dialogues, somatosensory interactions, expression interactions, and the like. In particular, the realization of natural language interaction requires the machine to understand human natural language. Conversational and QA interactions will gradually replace traditional keyword search interactions. Another important trend in conversational interaction is that everything can be answered. Our BOTs (dialogue robots) will take the place of reading articles, news, browsing graphs, videos, or even replacing movies, TV shows, and answering any questions we care about. The realization of natural human-machine interaction obviously requires a higher level of cognitive intelligence of the machine, and the machine has a strong background knowledge.
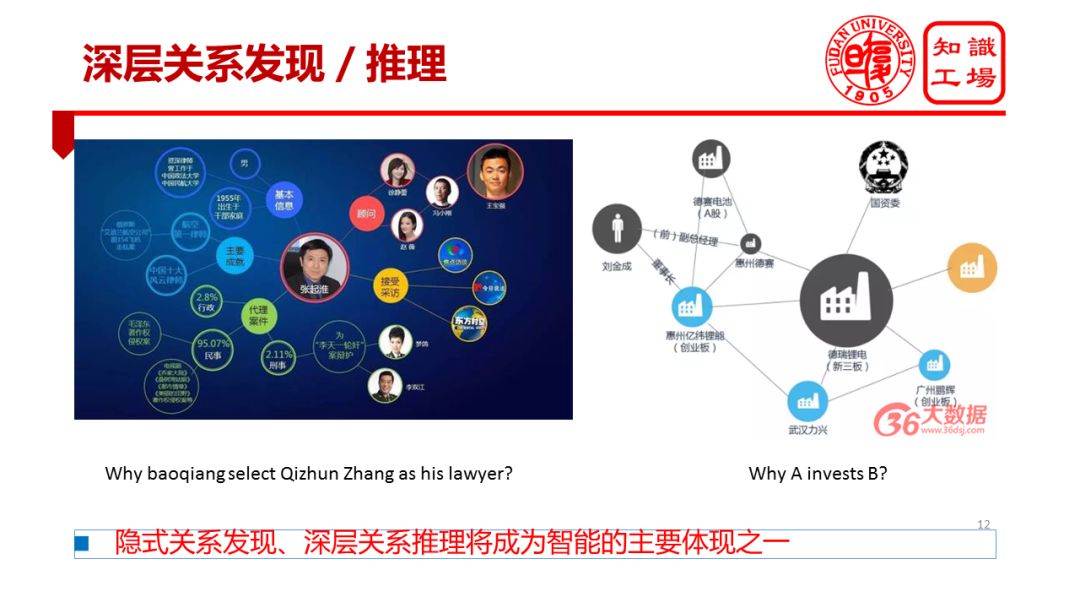
Cognitive intelligence is also reflected in the deep relationship discovery and reasoning capabilities of machines. People are increasingly dissatisfied with the discovery of simple associations such as "Ye Li is the wife of Yao Ming," but they want to discover and uncover some deep and hidden relationships. Here are some examples from the Internet. When Wang Baoqiang divorced, someone dug over why Wang Baoqiang was looking for Zhang Qihuai as a lawyer. Later, some people established the association maps and found that Wang Baoqiang and Feng Xiaogang had a good relationship. Feng Xiaogang had two actors who often cooperated with Xu Jinglei and Zhao Wei, and Zhang Qihuai was the legal advisor of the two actors. This relationship link has, to some extent, revealed the deep connection between Wang Baoqiang and his lawyers and also explains why Wang Baoqiang chose this lawyer. More similar examples occur in the financial sector. In the financial sector, we may be very concerned about investment relations, such as why an investor invests in a company; we are very concerned about financial security, such as credit risk assessment needs to analyze the credit rating of a lender's related affiliates and related companies.
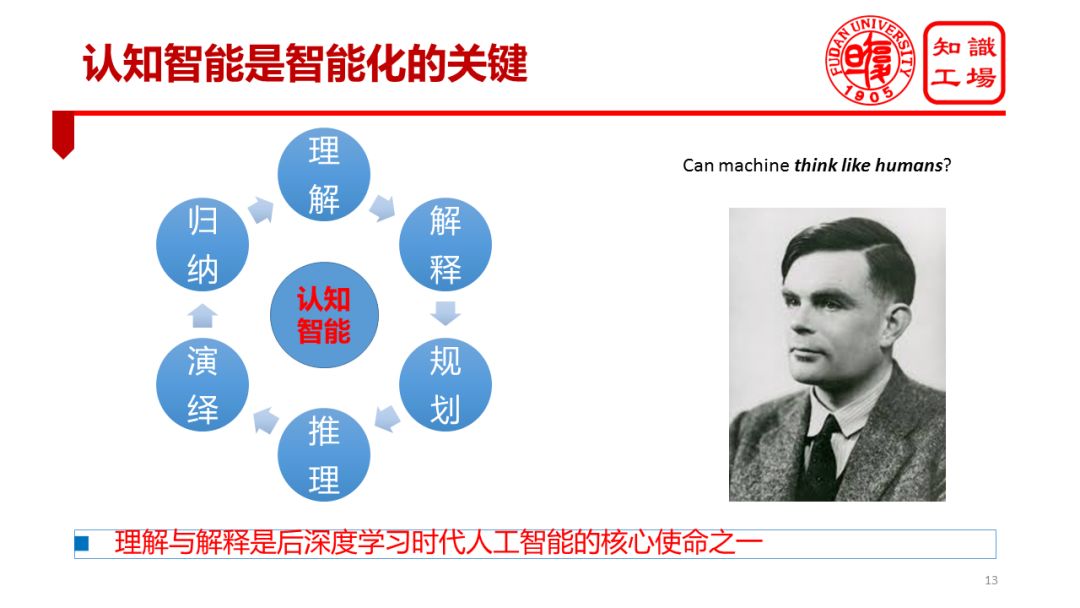
We can see that these requirements just mentioned are brewing and happening in various fields. These requirements require the machine to have cognitive ability and require the machine to have a series of capabilities such as understanding, explanation, planning, reasoning, deduction and induction. Among them, the understanding and interpretation are particularly prominent. It is not the question raised today that the machine has the cognitive ability. As far back as the Turing era, Alan Turing was thinking about designing a Turing Machine and was thinking that the machine could not think like a human being. The realization of machine-cognitive intelligence is essentially to make machines think like people.
There is a very important point to share with everyone. I believe that achieving cognitive intelligence is one of the important missions for AI development now and for some time to come. More specifically, understanding and interpreting will be one of the most important missions of artificial intelligence in the post-depth learning era. The reason for the post-deep learning era is that the development of deep learning has basically reached the end of the use of big data dividends, and deep learning is increasingly facing performance bottlenecks, and new ideas and directions need to be sought for breakthroughs. And a very important breakthrough direction lies in knowledge, which lies in the use of symbolic knowledge in the integration of symbolic knowledge and numerical models. The end result of these efforts is to give the machine the ability to understand and interpret.

How to achieve the machine's cognitive ability? Or more specifically, how can the machine have the ability to understand and explain? I believe that knowledge maps, or a series of technologies of knowledge engineering represented by knowledge maps, play a key role in the realization of cognitive intelligence. In a nutshell, the knowledge map is an enabler that implements machine intelligence. In other words, there is no knowledge map, and perhaps there is no realization of machine cognitive intelligence.
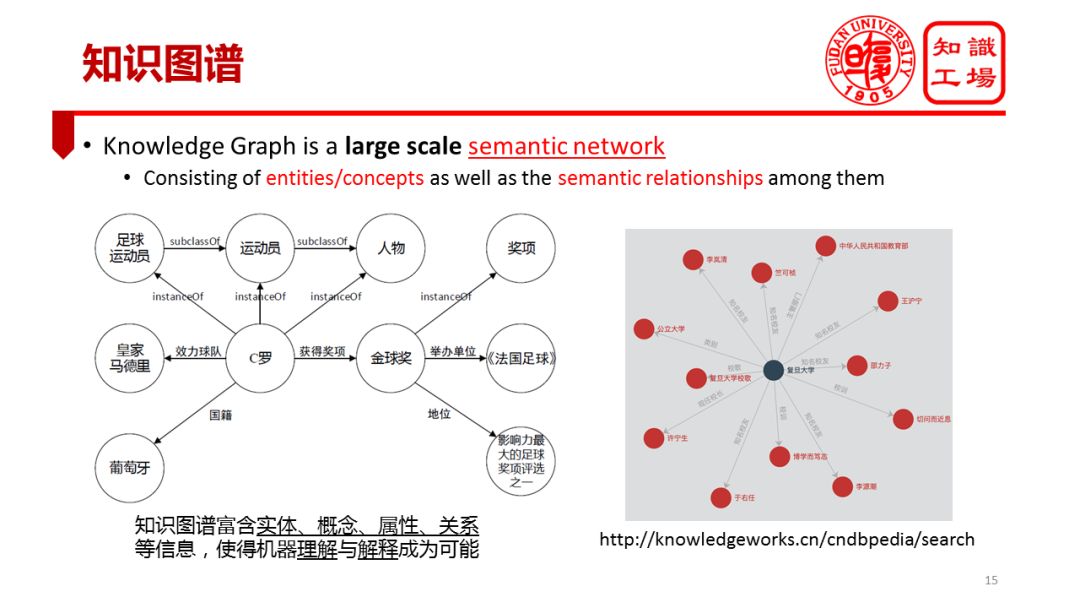
What is the knowledge map? I think the knowledge map is essentially a large-scale semantic network. To understand the concept of a knowledge map, there are two key words. The first is the semantic network. The semantic network expresses various entities, concepts, and various types of semantic associations between them. For example, "C Lo" is an entity. The "Golden Globe" is also an entity. There is a semantic relationship between them. Both "athletes" and "soccer players" are concepts, and the latter is a subclass of the former (corresponding to the subclassof relationship in the figure). The second keyword to understand the knowledge map is "large scale." Semantic networks are not new and existed as early as the prevalence of knowledge projects in the 1970s and 1980s. Compared to the semantic network of that era, the knowledge map is larger. This will be further described later.
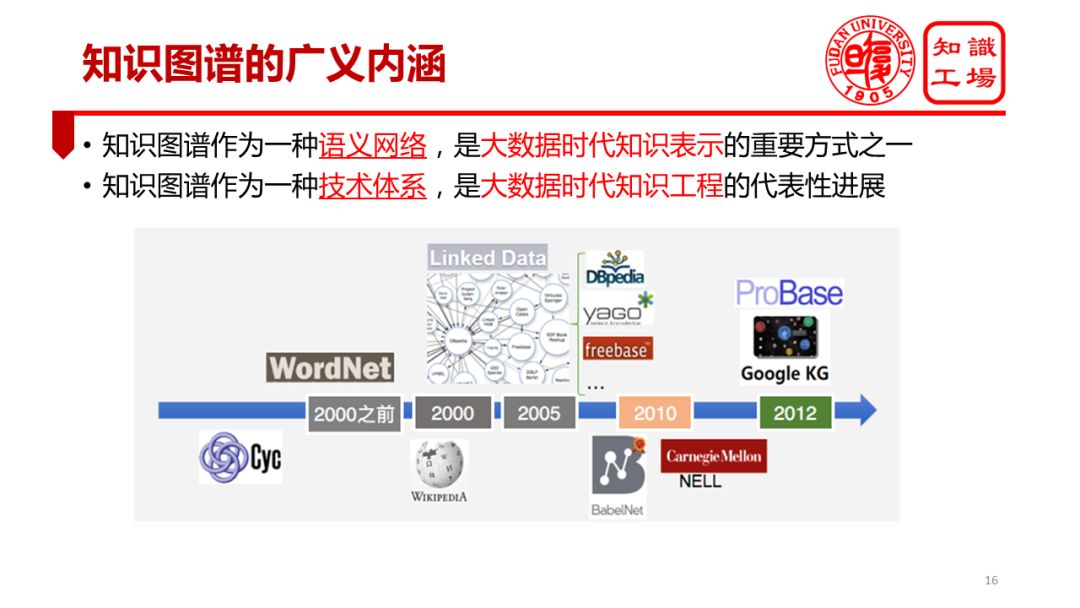
From Google's knowledge map to 2012, knowledge map technology has developed rapidly. The content of knowledge map far exceeds its narrow meaning as a semantic network. Now, in more practical contexts, the knowledge map is used as a technical system, referring to the sum of a series of representative technical developments of knowledge engineering in the era of big data. Last year, China's subject directory was adjusted, and the discipline orientation of knowledge maps appeared for the first time. The Ministry of Education's position on the subject of knowledge mapping is a "large-scale knowledge project." This position is very accurate and rich in meaning. It needs to be pointed out here that the development of knowledge mapping technology is a continuous and gradual process.
Starting from the flourishing of knowledge engineering in the 1970s and 1980s, academia and industry launched a series of knowledge bases. Until 2012, Google launched a large-scale knowledge base for Internet search, which is called Knowledge Mapping. To understand the connotation of today's knowledge map, it is impossible to separate its historical umbilical cord.
The historical development of the knowledge map will inevitably lead to a very interesting question. What is the essential difference between the knowledge representation in the 1970s and the 1980s and our knowledge map today? Under the leadership of the Turing prize winner Feigenbaum and AI pioneer Mawinsky, the knowledge project once flourished, solved a series of practical problems, and even achieved problems that seem difficult, such as mathematical theorem proving. Significant progress. Today, we once again discuss the knowledge map as a semantic network. Will it just be frying again? Is the knowledge map at the moment of the current fiery return of the knowledge project or is it again Zhongxing? This series of questions requires a reasonable answer.
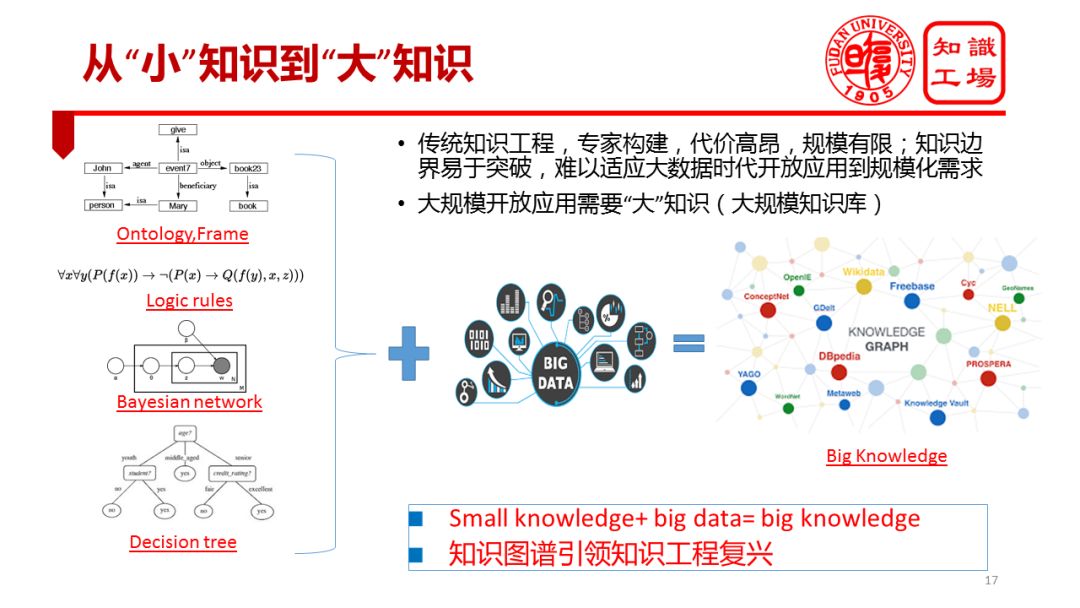
The difference between the traditional semantic network and the knowledge map is first shown on its scale. The knowledge map is a large-scale semantic network. Compared with various types of semantic networks in the 1970s and 1980s, the most significant difference is the scale difference. To expand widely, the fundamental difference between various knowledge representations and traditional knowledge representations in the era of big data represented by knowledge maps is first embodied in scale. A series of knowledge representation of traditional knowledge engineering is a typical “small knowledgeâ€. In the era of big data, benefiting from massive data, powerful computing capabilities, and intelligent computing, we are now able to automate building, or crowdsourcing, large-scale, high-quality knowledge bases to form so-called “big knowledge†(Hefei Industry). Professor Wu Xingdong of the University also mentioned similar views on many occasions.) Therefore, the difference between the knowledge map and the traditional knowledge expressed at the shallow level is the difference between the big knowledge and the small knowledge, and it is an obvious difference in scale.
A more profound analysis will reveal that such a change in the scale of knowledge brings about a qualitative change in the effectiveness of knowledge. Knowledge engineering disappeared after the 1980s. The fundamental reason is that the construction of traditional knowledge base mainly depends on manual construction, which is costly and limited in scale. For example, the word of Lin Lin in our country was compiled by tens of thousands of experts for more than 10 years, but it only has more than a hundred thousand entries. And now any knowledge map on the Internet, such as DBpedia, contains hundreds of millions of entities.
Although the artificially constructed knowledge base is of high quality, it is of limited scale. The limited scale makes traditional knowledge difficult to adapt to the needs of large-scale open applications in the Internet era. The characteristics of Internet applications are:
First, the scale is huge, we never know what the user's next search keyword is;
Second, the accuracy requirements are relatively low, and search engines never need to ensure that each search is understood and retrieved correctly;
Third, simple knowledge reasoning, most of the search understanding and answer only need to achieve simple reasoning, such as search for Andy Lau recommended songs, because it is known that Andy Lau is a singer, as "Yao Ming's wife's mother's son is how high," such complex reasoning in The actual application rate is not high.
The knowledge required for this kind of large-scale open application on the Internet can easily break through the knowledge boundary of the knowledge base preset by experts in the traditional expert system. I think this answer to a certain extent, why Google launched a knowledge map at this time in 2012, using a brand new name to express the attitude of resolutely breaking with traditional knowledge.
Some people may ask, then the expression of traditional knowledge should still be effective for field applications. Why did the expert system later become scarce in field applications?
I have also pondered this issue for a long time until I realized the interesting phenomenon of some knowledge applications in the application of knowledge mapping in many fields. I will call this phenomenon "pseudo closed domain knowledge" phenomenon. It seems that domain knowledge should be closed, that is, it will not spread beyond the boundaries of experts' preset knowledge.
However, the opposite is true. The application of knowledge in many fields is very easy to break through the previously set boundaries. For example, we now do financial knowledge maps. We originally thought that only stocks, futures, listed companies and finance were closely related. However, in practical applications, almost everything is related to finance in a certain sense. For example, a tornado may affect crops. The output, which in turn affects the shipment of agricultural machinery, has affected the agricultural engine and ultimately affected the stock price of the listed company. Isn't the correlation analysis like this exactly what we expect smart finance to achieve? Such deep correlation analysis is obviously very easy to exceed the preset knowledge boundary of any expert system. Therefore, in a certain sense, knowledge is universally related, and of course relevance is also conditional; the domain of domain knowledge is usually a false proposition, and the construction of a knowledge base in many fields must face the same challenges faced by the construction of a universal knowledge base.
In other words, the in-depth application of the domain knowledge base will necessarily involve a general knowledge base. This also explains, to a certain extent, one point that I once emphasized: The research of the universal knowledge base is of strategic importance and should not be lost; 10,000 fields of knowledge research are not transparent, and there may not be a universal knowledge base to study the thorough value. It's high. The study of the universal knowledge base is to seize the strategic high ground of the research of the knowledge base, and it can form a strategic dive for the domain knowledge base.
If you are still not satisfied with my current answer, further questioning determines what the root cause of the sticky nature of domain knowledge bases and general knowledge bases is. Then I think the answer lies in the human knowledge system. Our knowledge is based on an architecture. The bottom of the architecture is the knowledge that supports the entire knowledge system as a foundation. The bottom line in general knowledge should be common sense, that is, knowledge that we all know, especially our basic human knowledge of time, space, and cause and effect. The entire knowledge system is based on these general common sense, and then uses metaphor as the main means to gradually form our high-level, abstract or domain knowledge.
Therefore, I want to use a simple formula to show the connection and difference between traditional knowledge engineering and a new generation of knowledge engineering represented by knowledge maps: Small knowledge + Big data = Big knowledge. This formula expresses two levels of meaning. I. The Knowledge Project The knowledge project of the big data era has a long history; knowledge maps are derived from traditional knowledge representations, but are significantly superior to traditional semantic networks in scale; and this quantitative change also brings qualitative changes in knowledge effectiveness. . The meaning of this layer has just been explained and will not be repeated. What I want to emphasize through this formula is another layer of meaning: There are a large number of traditional knowledge representations. Through the empowerment of big data, these knowledge representations will exert tremendous energy in various application scenarios. Knowledge maps are merely a significant increase in the scale of traditional semantic networks, and they have been able to solve a large number of practical problems.
Imagine that we have a large number of other knowledge representations, such as ontology, framework, predicate logic, Markov logic networks, decision trees, etc. All kinds of knowledge representations are still locked in the cage of scale. Once the scale bottleneck is broken, I It is believed that the entire industry of knowledge engineering will be greatly released. It is in this sense that I believe that knowledge maps are just a prelude to the revival of knowledge engineering, and knowledge maps will lead the revival of knowledge engineering. I have a strong feeling. For example, we have experienced the dynamic transition from small data to big data. We are also bound to experience the transition from small knowledge to big knowledge.
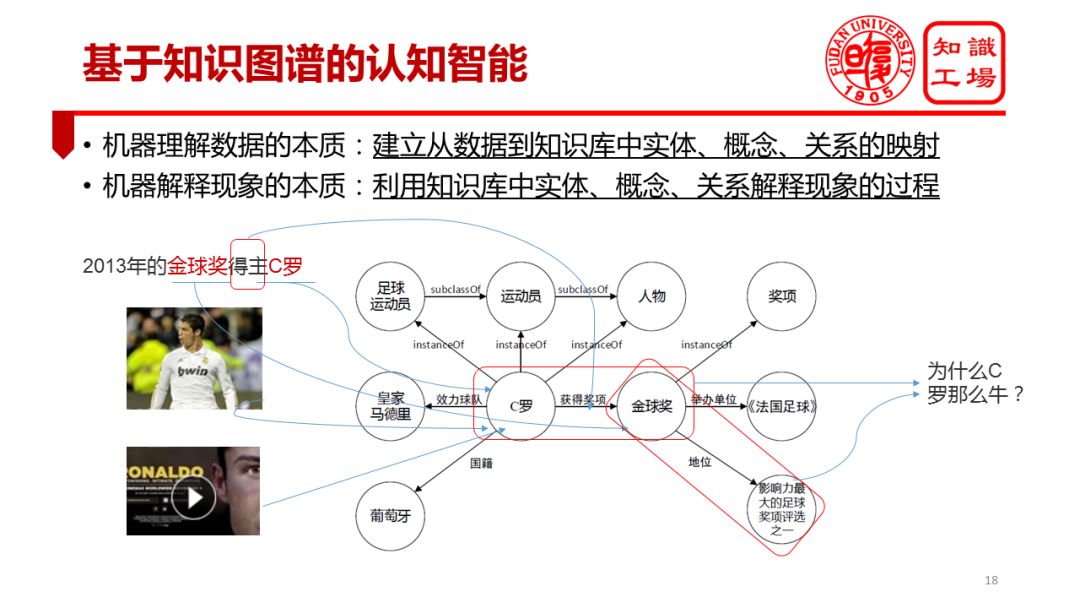
Why is knowledge mapping so important for machines implementing artificial intelligence? We first analyze this issue from a metaphysical perspective. Specifically, we analyze the two core competencies of knowledge mapping to achieve machine cognitive intelligence: "understand" and "explain." I try to give an explanation to the machine "understand and explain". I think the essence of machine understanding of data is a process of mapping from data to knowledge elements (including entities, concepts, and relationships) in the knowledge base.
For example, if I say the phrase "2013 Cristiano Ronaldo award-winning Cristiano Ronaldo", we say that we understand this sentence because we associate the term "Cro" with the entity in our head "C. "Luo" maps the term "Golden Globe Award" to the entity "Golden Globe Award" in our mind, and then maps the word "winner" to the "winning award" relationship.
We can carefully understand our text understanding process. Its essence is to establish the process of mapping entities, concepts, and attributes from data, including text, pictures, voice, video, and other data, into the knowledge base. Let's look at how we humans "interpret". For example, I asked “Why are Cristiano Ronaldo so?â€. We can explain this through the relationship between “Cristiano Ronaldo won the Golden Globe Award†and “one of the Golden Ball Prize's most influential football awardsâ€. One problem. The essence of this process is the process of associating knowledge and problems or data in the knowledge base. With knowledge maps, the machine can fully reproduce our understanding and interpretation process. It is not difficult to complete the mathematical modeling of the above process based on certain computer research.

The necessity of knowledge mapping for machine-cognitive intelligence can also be elaborated from several specific issues.
First, we look at one of the core competencies of machine cognition: natural language understanding. My point is that machine understanding of natural language requires background knowledge such as similar knowledge maps. Natural language is extremely complex: natural language is ambiguous and diverse, semantic understanding is ambiguous and context-dependent.机器ç†è§£è‡ªç„¶è¯è¨€å›°éš¾çš„æ ¹æœ¬åŽŸå› åœ¨äºŽï¼Œäººç±»è¯è¨€ç†è§£æ˜¯å»ºç«‹åœ¨äººç±»çš„认知能力基础之上的,人类的认知体验所形æˆçš„背景知识是支撑人类è¯è¨€ç†è§£çš„æ ¹æœ¬æ”¯æŸ±ã€‚
我们人类彼æ¤ä¹‹é—´çš„è¯è¨€ç†è§£å°±å¥½æ¯”æ˜¯æ ¹æ®å†°å±±ä¸Šæµ®å‡ºæ°´é¢çš„一角æ¥æ£æµ‹å†°å±±ä¸‹çš„部分。我们之所以能够很自然地ç†è§£å½¼æ¤çš„è¯è¨€ï¼Œæ˜¯å› 为彼æ¤å…±äº«ç±»ä¼¼çš„生活体验ã€ç±»ä¼¼çš„教育背景,从而有ç€ç±»ä¼¼çš„背景知识。冰山下庞大的背景知识使得我们å¯ä»¥å½¼æ¤ç†è§£æ°´é¢ä¸Šæœ‰é™çš„å‡ ä¸ªå—符。我们å¯ä»¥åšä¸ªç®€å•çš„æ€æƒ³å®žéªŒï¼Œå‡å¦‚现在有个外星人å在这里å¬æˆ‘讲报告,他能å¬æ‡‚ä¹ˆï¼Ÿæˆ‘æƒ³è¿˜æ˜¯å¾ˆå›°éš¾çš„ï¼Œå› ä¸ºä»–æ²¡æœ‰åœ¨åœ°çƒä¸Šç”Ÿæ´»çš„ç»åŽ†ï¼Œæ²¡æœ‰ä¸Žæˆ‘相类似的教育背景,没有与我类似的背景知识库。
å†ä¸¾ä¸ªå¾ˆå¤šäººéƒ½æœ‰ä½“会的例å,我们去å‚åŠ å›½é™…ä¼šè®®æ—¶ï¼Œç»å¸¸é‡åˆ°ä¸€ä¸ªå°´å°¬çš„å±€é¢ï¼Œå°±æ˜¯è¥¿æ–¹å¦è€…说的笑è¯ï¼Œæˆ‘ä»¬ä¸œæ–¹äººå¾ˆéš¾äº§ç”Ÿå…±é¸£ã€‚å› ä¸ºæˆ‘ä»¬å’Œä»–ä»¬çš„èƒŒæ™¯çŸ¥è¯†åº“ä¸åŒï¼Œæˆ‘们早é¤åƒçƒ§é¥¼ã€æ²¹æ¡ï¼Œè¥¿æ–¹åƒå’–å•¡ã€é¢åŒ…,ä¸åŒçš„背景知识决定了我们对幽默有ç€ä¸åŒçš„ç†è§£ã€‚所以è¯è¨€ç†è§£éœ€è¦èƒŒæ™¯çŸ¥è¯†ï¼Œæ²¡æœ‰å¼ºå¤§çš„背景知识支撑,是ä¸å¯èƒ½ç†è§£è¯è¨€çš„。è¦è®©æœºå™¨ç†è§£æˆ‘们人类的è¯è¨€ï¼Œæœºå™¨å¿…需共享与我们类似的背景知识。

实现机器自然è¯è¨€ç†è§£æ‰€éœ€è¦çš„背景知识是有ç€è‹›åˆ»çš„æ¡ä»¶çš„:规模足够大ã€è¯ä¹‰å…³ç³»è¶³å¤Ÿä¸°å¯Œã€ç»“构足够å‹å¥½ã€è´¨é‡è¶³å¤Ÿç²¾è‰¯ã€‚以这四个æ¡ä»¶åŽ»çœ‹çŸ¥è¯†è¡¨ç¤ºå°±ä¼šå‘现,åªæœ‰çŸ¥è¯†å›¾è°±æ˜¯æ»¡è¶³æ‰€æœ‰è¿™äº›æ¡ä»¶çš„:知识图谱规模巨大,动辄包å«æ•°åäº¿å®žä½“ï¼›å…³ç³»å¤šæ ·ï¼Œæ¯”å¦‚åœ¨çº¿ç™¾ç§‘å›¾è°±DBpedia包å«æ•°åƒç§å¸¸è§è¯ä¹‰å…³ç³»ï¼›ç»“æž„å‹å¥½ï¼Œé€šå¸¸è¡¨è¾¾ä¸ºRDF三元组,这是一ç§å¯¹äºŽæœºå™¨è€Œè¨€èƒ½å¤Ÿæœ‰æ•ˆå¤„ç†çš„结构;质é‡ä¹Ÿå¾ˆç²¾è‰¯ï¼Œå› 为知识图谱å¯ä»¥å……分利用大数æ®çš„多æºç‰¹æ€§è¿›è¡Œäº¤å‰éªŒè¯ï¼Œä¹Ÿå¯åˆ©ç”¨ä¼—包ä¿è¯çŸ¥è¯†åº“è´¨é‡ã€‚所以知识图谱æˆä¸ºäº†è®©æœºå™¨ç†è§£è‡ªç„¶è¯è¨€æ‰€éœ€çš„背景知识的ä¸äºŒé€‰æ‹©ã€‚
既然机器ç†è§£è‡ªç„¶è¯è¨€éœ€è¦èƒŒæ™¯çŸ¥è¯†ï¼Œæˆ‘对于当å‰çš„自然è¯è¨€å¤„ç†æœ‰ä¸ªé‡è¦çœ‹æ³•ï¼šæˆ‘认为自然è¯è¨€å¤„ç†èµ°å‘自然è¯è¨€ç†è§£çš„å¿…ç»ä¹‹è·¯æ˜¯çŸ¥è¯†ï¼Œæˆ‘将我的这个观点表达为NLP+KB=NLUçš„å…¬å¼ã€‚很多NLP从业人员有个体会,明明论文里é¢æŠ¥é“的在æŸä¸ªbenchmarkæ•°æ®95%准确率的模型一旦用到实际数æ®ä¸Šï¼Œè‡³å°‘有10个百分点的下é™ã€‚而最åŽé‚£å‡ 个点的准确率的æå‡éœ€è¦æœºå™¨ç†è§£è‡ªç„¶è¯è¨€ã€‚这一点在å¸æ³•ã€é‡‘èžã€åŒ»ç–—ç‰çŸ¥è¯†å¯†é›†åž‹çš„应用领域已ç»ä½“现的éžå¸¸æ˜Žæ˜¾äº†ã€‚比如在å¸æ³•é¢†åŸŸï¼Œå¦‚æžœä¸æŠŠå¸æ³•èƒŒåŽçš„事ç†é€»è¾‘ã€çŸ¥è¯†ä½“系赋予机器,å•çº¯ä¾èµ–å—符数æ®çš„处ç†ï¼Œæ˜¯éš¾ä»¥å®žçŽ°å¸æ³•æ•°æ®çš„è¯ä¹‰ç†è§£çš„,是难以满足å¸æ³•æ–‡æœ¬çš„智能化处ç†éœ€æ±‚的。
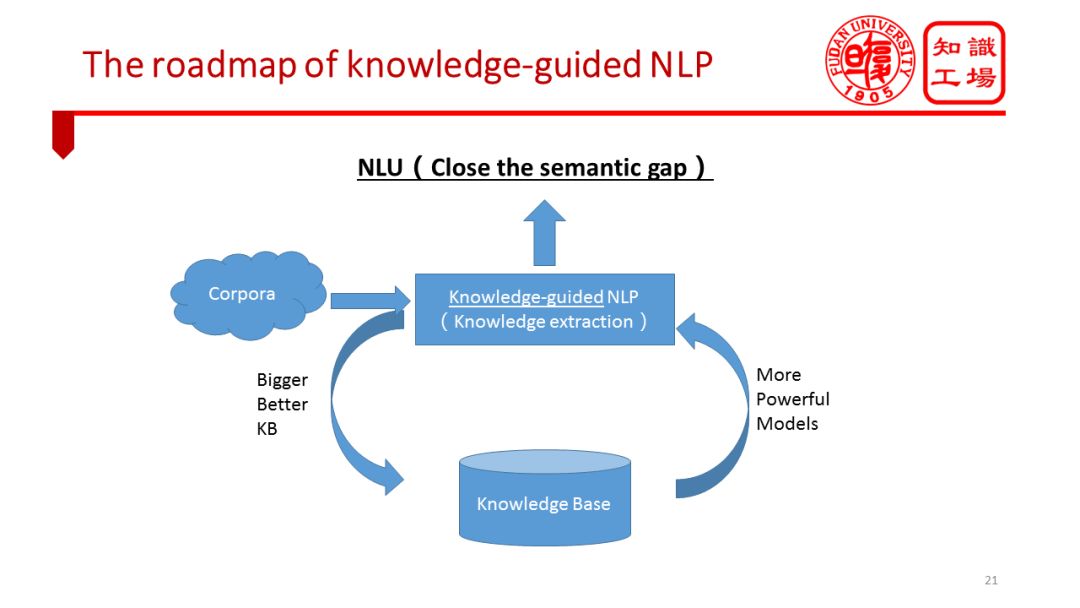
å› æ¤ï¼ŒNLP将会越æ¥è¶Šå¤šåœ°èµ°å‘知识引导的é“路。NLP与KB将走å‘一æ¡äº¤è¿æ¼”进的é“路。在知识的引导下,NLP模型的能力越æ¥è¶Šå¼ºï¼Œè¶Šæ¥è¶Šå¼ºå¤§çš„NLP模型,特别是从文本ä¸è¿›è¡ŒçŸ¥è¯†æŠ½å–的相关模型,将会帮助我们实现更为精准地ã€è‡ªåŠ¨åŒ–抽å–,从而形æˆä¸€ä¸ªè´¨é‡æ›´å¥½ã€è§„模更大的知识库。更好的知识库åˆå¯ä»¥è¿›ä¸€æ¥å¢žå¼ºNLP模型。这ç§å¾ªçŽ¯è¿ä»£æŒç»ä¸‹åŽ»ï¼ŒNLP最åŽå°†ä¼šéžå¸¸æŽ¥è¿‘NLU,甚至最终克æœè¯ä¹‰é¸¿æ²Ÿï¼Œå®žçŽ°æœºå™¨çš„自然è¯è¨€ç†è§£ã€‚
æœ€è¿‘å‡ å¹´ï¼Œè¿™æ¡æŠ€æœ¯æ¼”进路线日æ¸æ¸…晰,越æ¥è¶Šå¤šçš„顶尖å¦è€…有ç€ä¸Žæˆ‘ç±»ä¼¼çš„çœ‹æ³•ï¼Œæˆ‘çš„ç ”ç©¶å›¢é˜Ÿæ²¿ç€è¿™æ¡è·¯å¾„åšäº†å¾ˆå¤šå°è¯•ï¼Œåˆæ¥çœ‹æ¥æ•ˆæžœæ˜¾è‘—。当然这些都是一家之言。也有ä¸å°‘人认为ä¾é 纯数æ®é©±åŠ¨çš„自然è¯è¨€å¤„ç†æ¨¡åž‹ä¹Ÿå¯å®žçŽ°æœºå™¨çš„自然è¯è¨€ç†è§£ï¼Œç‰¹åˆ«æ˜¯å½“下深度å¦ä¹ 在自然è¯è¨€å¤„ç†æ–¹é¢è¿˜å分æµè¡Œï¼Œæˆ‘所倡导的知识引导下的NLPå‘展路径多少有些显得ä¸åˆæ—¶å®œã€‚

这里,通过一个实际案例论è¯çŸ¥è¯†å¯¹äºŽNLPçš„é‡è¦ä½œç”¨ã€‚在问ç”ç ”ç©¶ä¸ï¼Œè‡ªç„¶è¯è¨€é—®é¢˜çš„ç†è§£æˆ–者è¯ä¹‰è¡¨ç¤ºæ˜¯ä¸€ä¸ªéš¾é¢˜ã€‚
åŒæ ·è¯ä¹‰çš„问题表达方å¼å¾€å¾€æ˜¯å¤šæ ·çš„,比如ä¸è®ºæ˜¯how many people are there in Shanghai? 还是what isthe population of Shanghai,都是在问上海人å£ã€‚åˆæˆ–者形å¼ä¸Šçœ‹ä¸ŠåŽ»å¾ˆæŽ¥è¿‘的问题,实质è¯ä¹‰ç›¸å·®å¾ˆå¤§ï¼Œæ¯”如“狗咬人了å—â€ä¸Žâ€œäººå’¬ç‹—了å—â€è¯ä¹‰å®Œå…¨ä¸åŒã€‚
当问题ç”案æ¥è‡ªäºŽçŸ¥è¯†åº“时,这类问题就属于KBQA(é¢å‘知识库的自然è¯è¨€é—®ç”ï¼‰çš„ç ”ç©¶å†…å®¹ã€‚KBQAçš„æ ¸å¿ƒæ¥éª¤æ˜¯å»ºç«‹ä»Žè‡ªç„¶è¯è¨€é—®é¢˜åˆ°çŸ¥è¯†åº“ä¸çš„三元组谓è¯çš„æ˜ å°„å…³ç³»ã€‚æ¯”å¦‚ä¸Šé¢çš„两个与上海人å£ç›¸å…³çš„问题,都å¯ä»¥æ˜ 射到知识库ä¸çš„Population这个谓è¯ã€‚一ç§ç®€å•çš„办法是让机器记ä½é—®é¢˜åˆ°è°“è¯çš„æ˜ å°„è§„åˆ™ï¼Œæ¯”å¦‚æœºå™¨è®°ä½â€œHow many people are there in Shanghai?â€æ˜ 射到上海这个实体的Populationè°“è¯ä¸Šã€‚但这ç§æ–¹æ³•æ²¡æœ‰æŠŠæ¡é—®é¢˜è¯ä¹‰æœ¬è´¨ï¼Œå¦‚果用åŒæ ·çš„å¥å¼é—®åŠåŒ—京ã€å—京,甚至任何一个城市人å£å‘¢ï¼Ÿéš¾é“机器需è¦ä¸ºæ¯ä¸ªå®žä¾‹è®°ä½è¿™äº›æ˜ 射么?显然我们人类ä¸æ˜¯å¦‚æ¤ç†è§£é—®é¢˜è¯ä¹‰çš„,我们是在“How many people are there in $City?â€è¿™ä¸ªé—®é¢˜æ¦‚念模æ¿å±‚次把æ¡é—®é¢˜è¯ä¹‰çš„实质的。利用概念模æ¿ä¸ä»…é¿å…了暴力å¼çš„记忆,åŒæ—¶ä¹Ÿèƒ½è®©æœºå™¨å…·å¤‡ç±»äººçš„推ç†èƒ½åŠ›ã€‚
比如,如果问到“How many people are there in XXX?â€ï¼Œæœºå™¨åªè¦çŸ¥é“XXX是个city,那么这个问题一定是在问XXX的人å£æ•°é‡ã€‚那么我们怎么生æˆè¿™ç§é—®é¢˜æ¦‚念模æ¿å‘¢ï¼Œæˆ‘们用概念图谱。概念图谱里é¢å«æœ‰å¤§é‡çš„类似shanghai isa city,beijing isa city 这类知识。充分利用这些知识å¯ä»¥å¾—到自然è¯è¨€é—®é¢˜çš„有效表示,从而实现机器对于自然è¯è¨€é—®é¢˜çš„è¯ä¹‰ç†è§£ã€‚
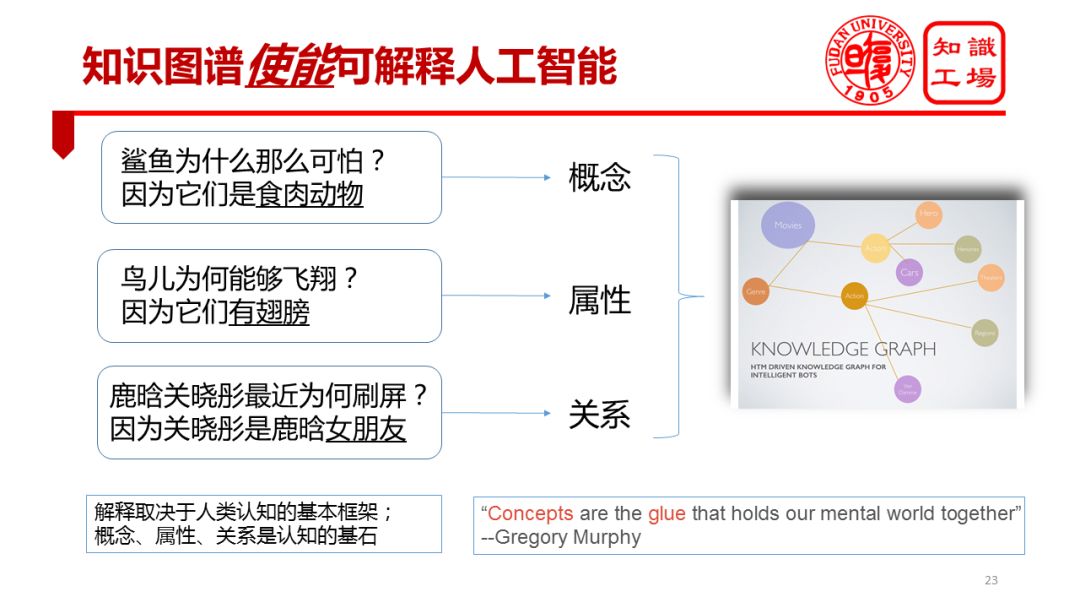
知识图谱对于认知智能的å¦ä¸€ä¸ªé‡è¦æ„义在于:知识图谱让å¯è§£é‡Šäººå·¥æ™ºèƒ½æˆä¸ºå¯èƒ½ã€‚“解释â€è¿™ä»¶äº‹æƒ…一定是跟符å·åŒ–çŸ¥è¯†å›¾è°±å¯†åˆ‡ç›¸å…³çš„ã€‚å› ä¸ºè§£é‡Šçš„å¯¹è±¡æ˜¯äººï¼Œäººåªèƒ½ç†è§£ç¬¦å·ï¼Œæ²¡åŠžæ³•ç†è§£æ•°å€¼ï¼Œæ‰€ä»¥ä¸€å®šè¦åˆ©ç”¨ç¬¦å·çŸ¥è¯†å¼€å±•å¯è§£é‡Šäººå·¥æ™ºèƒ½çš„ç ”ç©¶ã€‚å¯è§£é‡Šæ€§æ˜¯ä¸èƒ½å›žé¿ç¬¦å·çŸ¥è¯†çš„。
我们先æ¥çœ‹å‡ 个解释的具体例å。比如,我若问鲨鱼为什么å¯æ€•ï¼Ÿä½ å¯èƒ½è§£é‡Šè¯´ï¼šå› ä¸ºé²¨é±¼æ˜¯é£Ÿè‚‰åŠ¨ç‰©ï¼Œè¿™å®žè´¨ä¸Šæ˜¯ç”¨æ¦‚å¿µåœ¨è§£é‡Šã€‚è‹¥é—®é¸Ÿä¸ºä»€ä¹ˆèƒ½é£žç¿”ï¼Ÿä½ å¯èƒ½ä¼šè§£é‡Šå› 为它有翅膀。这是用属性在解释。若问鹿晗关晓彤å‰äº›æ—¥å为什么会刷å±ï¼Ÿä½ å¯èƒ½ä¼šè§£é‡Šè¯´å› 为关晓彤是鹿晗的女朋å‹ã€‚这是用关系在解释。我们人类倾å‘于利用概念ã€å±žæ€§ã€å…³ç³»è¿™äº›è®¤çŸ¥çš„åŸºæœ¬å…ƒç´ åŽ»è§£é‡ŠçŽ°è±¡ï¼Œè§£é‡Šäº‹å®žã€‚è€Œå¯¹äºŽæœºå™¨è€Œè¨€ï¼Œæ¦‚å¿µã€å±žæ€§å’Œå…³ç³»éƒ½è¡¨è¾¾åœ¨çŸ¥è¯†å›¾è°±é‡Œé¢ã€‚å› æ¤ï¼Œè§£é‡Šç¦»ä¸å¼€çŸ¥è¯†å›¾è°±ã€‚

沿ç€è¿™ä¸ªæ€è·¯ï¼Œæˆ‘们åšäº†ä¸€äº›åˆæ¥å°è¯•ï¼Œæˆ‘们首先试ç€åˆ©ç”¨çŸ¥è¯†å›¾è°±åšå¯è§£é‡ŠæŽ¨è。我们目å‰çš„互è”网推è,åªèƒ½ç»™æˆ‘们推è结果,å´æ— 法解释为什么。å¯è§£é‡ŠæŽ¨è将是未æ¥æŽ¨èç ”ç©¶çš„é‡è¦é¢†åŸŸï¼Œå°†æ˜¯å…·æœ‰å·¨å¤§å•†ä¸šä»·å€¼çš„ç ”ç©¶è¯¾é¢˜ã€‚æˆ‘ä»¬åˆæ¥å®žçŽ°äº†å¯è§£é‡Šçš„实体推è。若用户æœç´¢äº†â€œç™¾åº¦â€å’Œâ€œé˜¿é‡Œâ€ï¼Œæœºå™¨æŽ¨è“腾讯â€ï¼Œå¹¶ä¸”解释为什么推è“腾讯â€ï¼Œå› 为他们都是互è”网巨头ã€éƒ½æ˜¯å¤§åž‹ITå…¬å¸ã€‚这里实质上是在利用概念展开解释,这些概念å¯ä»¥åœ¨å¾ˆå¤šæ¦‚念图谱,比如英文概念图谱Probase,和ä¸æ–‡æ¦‚念图谱CN-Probase里找到。
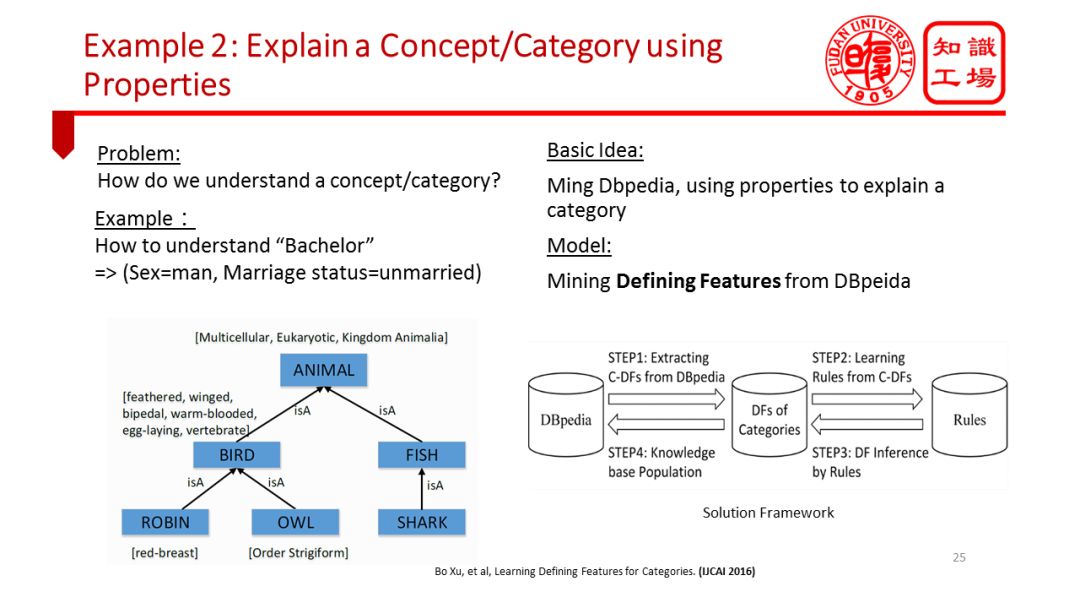
å¦ä¸€ä¸ªä¾‹å是让机器解释概念。比如å‘机器æåŠâ€œå•èº«æ±‰â€è¿™ä¸ªæ¦‚念,机器能å¦è‡ªåŠ¨äº§ç”Ÿâ€œç”·æ€§â€ã€â€œæœªå©šâ€è¿™æ ·çš„属性用于解释这个概念。我们针对富å«å®žä½“ã€æ¦‚念和属性信æ¯çš„大型百科图谱展开挖掘,自动挖掘出常è§æ¦‚念的定义性属性。这些定义性属性å¯ä»¥å¸®åŠ©æˆ‘们完善概念图谱,也就是为概念图谱上的æ¯ä¸ªæ¦‚念补充定义性属性信æ¯ï¼›è¿›ä¸€æ¥å¯ä»¥åˆ©ç”¨è¿™äº›ä¿¡æ¯è®©æœºå™¨åˆ©ç”¨å±žæ€§å¯¹äºŽå®žä½“进行准确归类。这一归类过程本质上是在模拟人类的范畴化过程。
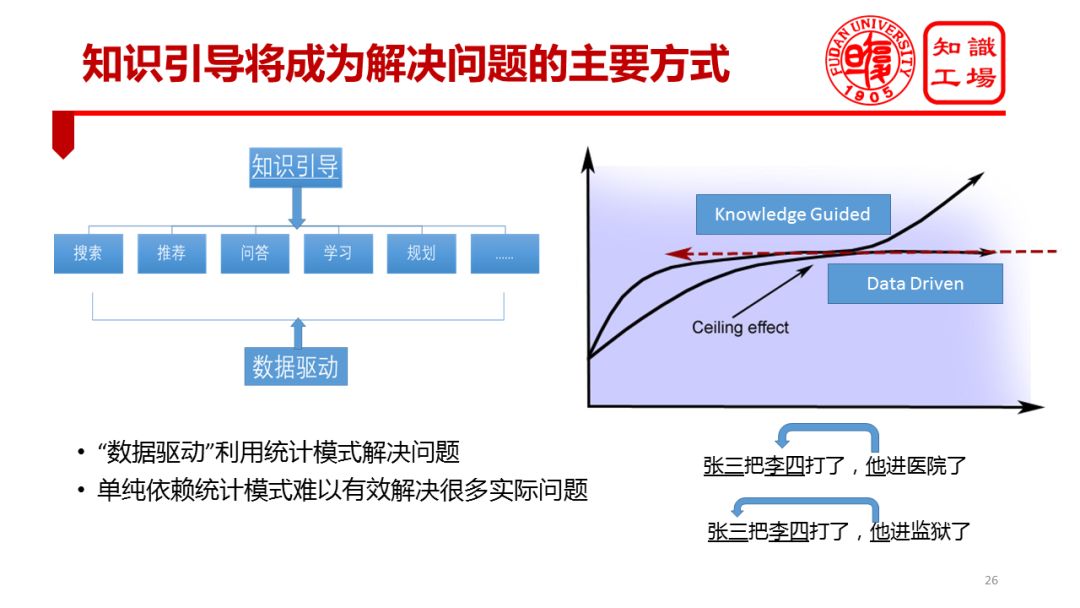
知识图谱的å¦ä¸€ä¸ªé‡è¦ä½œç”¨ä½“现在知识引导将æˆä¸ºè§£å†³é—®é¢˜çš„主è¦æ–¹å¼ã€‚å‰é¢å·²ç»å¤šæ¬¡æåŠç”¨æˆ·å¯¹ä½¿ç”¨ç»Ÿè®¡æ¨¡åž‹æ¥è§£å†³é—®é¢˜çš„效果越æ¥è¶Šä¸æ»¡æ„了,统计模型的效果已ç»æŽ¥è¿‘“天花æ¿â€ï¼Œè¦æƒ³çªç ´è¿™ä¸ªâ€œå¤©èŠ±æ¿â€ï¼Œéœ€è¦çŸ¥è¯†å¼•å¯¼ã€‚
举个例åï¼Œå®žä½“æŒ‡ä»£è¿™æ ·çš„æ–‡æœ¬å¤„ç†éš¾é¢˜ï¼Œæ²¡æœ‰çŸ¥è¯†å•çº¯ä¾èµ–æ•°æ®æ˜¯éš¾ä»¥å–å¾—ç†æƒ³æ•ˆæžœçš„ã€‚æ¯”å¦‚â€œå¼ ä¸‰æŠŠæŽå››æ‰“了,他进医院了â€å’Œâ€œå¼ 三把æŽå››æ‰“了,他进监狱了â€ï¼Œäººç±»å¾ˆå®¹æ˜“确定这两个ä¸åŒçš„“他â€çš„åˆ†åˆ«æŒ‡ä»£ã€‚å› ä¸ºäººç±»æœ‰çŸ¥è¯†ï¼Œæœ‰å…³äºŽæ‰“äººè¿™ä¸ªåœºæ™¯çš„åŸºæœ¬çŸ¥è¯†ï¼ŒçŸ¥é“打人的往往è¦è¿›ç›‘狱,而被打的往往会进医院。但是当å‰æœºå™¨ç¼ºä¹è¿™äº›çŸ¥è¯†ï¼Œæ‰€ä»¥æ— 法准确识别代è¯çš„准确指代。很多任务是纯粹的基于数æ®é©±åŠ¨çš„模型所解决ä¸äº†çš„,知识在很多任务里ä¸å¯æˆ–缺。比较务实的åšæ³•æ˜¯å°†è¿™ä¸¤ç±»æ–¹æ³•æ·±åº¦èžåˆã€‚

实际上在很多NLP应用问题ä¸ï¼Œæˆ‘们在å°è¯•ç”¨çŸ¥è¯†å¼•å¯¼çªç ´æ€§èƒ½ç“¶é¢ˆã€‚比如在ä¸æ–‡å®žä½“识别与链接ä¸ï¼Œé’ˆå¯¹ä¸æ–‡çŸæ–‡æœ¬ï¼Œåœ¨å¼€æ”¾è¯å¢ƒä¸‹ï¼Œåœ¨æ²¡æœ‰å……分上下文,缺ä¹ä¸»é¢˜ä¿¡æ¯çš„å‰æ下,这一问题ä»ç„¶å分困难,现在工业界最高准确率大概60%多的水平。当å‰æœºå™¨ä»ç„¶éš¾ä»¥ç†è§£ä¸æ–‡æ–‡æœ¬ä¸çš„实体。最近,我们利用ä¸æ–‡æ¦‚念图谱CN-Probase,给予ä¸æ–‡å®žä½“识别与链接任务以丰富的背景知识,å–得了å分显著的效果。我们知é“打çƒçš„æŽå¨œå’Œå”±æŒçš„æŽå¨œä¸æ˜¯åŒä¸€ä¸ªäººï¼ŒçŽ°åœ¨å³ä¾¿è¿™ä¸¤äººåœ¨æ–‡æœ¬ä¸åŒæ—¶è¢«æåŠï¼Œæœºå™¨ä¹Ÿèƒ½å‡†ç¡®è¯†åˆ«å¹¶åŠ 以区分。
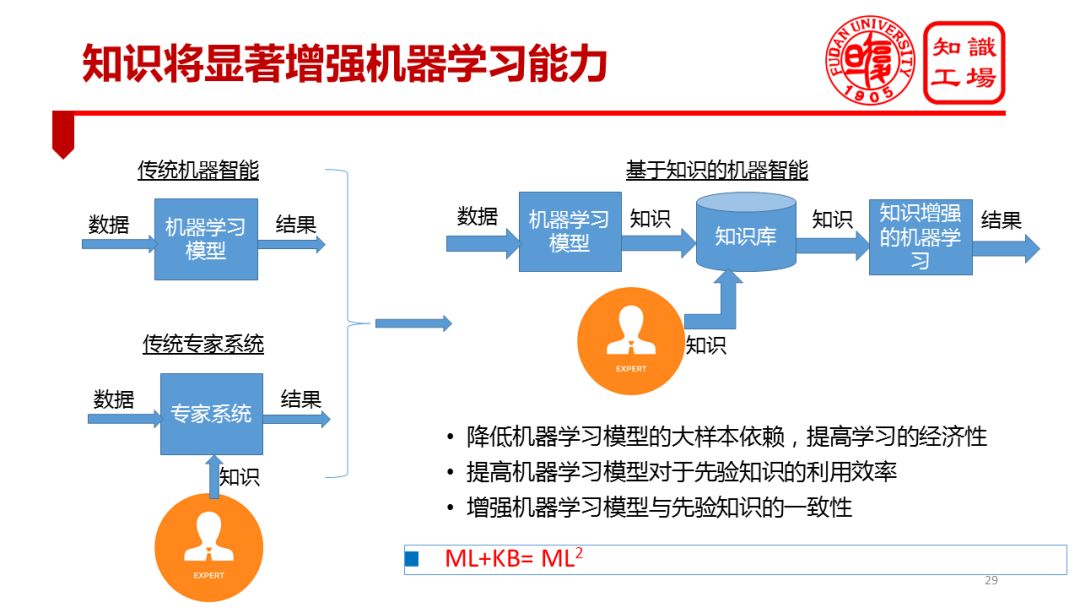
知识对于认知智能åˆä¸€ä¸ªå¾ˆé‡è¦çš„æ„义就是将显著增强机器å¦ä¹ 的能力。
当å‰çš„机器å¦ä¹ 是一ç§å…¸åž‹çš„“机械å¼â€å¦ä¹ æ–¹å¼ï¼Œä¸Žäººç±»çš„å¦ä¹ æ–¹å¼ç›¸æ¯”显得比较笨拙。我们的å©ç«¥åªéœ€è¦çˆ¶æ¯å‘ŠçŸ¥ä¸€ä¸¤æ¬¡ï¼šè¿™æ˜¯çŒ«ï¼Œé‚£æ˜¯ç‹—,就能有效识别或者区分猫狗。而机器å´éœ€è¦æ•°ä»¥ä¸‡è®¡çš„æ ·æœ¬æ‰èƒ½ä¹ 得猫狗的特å¾ã€‚我们ä¸å›½å¦ä¹ 英è¯ï¼Œè™½ç„¶ä¹Ÿè¦è‹¥å¹²å¹´æ‰èƒ½å°æœ‰æ‰€æˆï¼Œä½†ç›¸å¯¹äºŽæœºå™¨å¯¹äºŽè¯è¨€çš„å¦ä¹ 而言è¦é«˜æ•ˆçš„多。
机器å¦ä¹ 模型è½åœ°åº”用ä¸çš„一个常è§é—®é¢˜æ˜¯ä¸Žä¸“家知识或判æ–ä¸ç¬¦åˆï¼Œè¿™ä½¿æˆ‘们很快陷入进退两难的境地:是相信å¦ä¹ 模型还是果æ–弃之?机器å¦ä¹ 与人类å¦ä¹ çš„æ ¹æœ¬å·®å¼‚å¯ä»¥å½’结为人是有知识的且能够有效利用知识的物ç§ã€‚
我相信,未æ¥æœºå™¨å¦ä¹ 能力的显著增强也è¦èµ°ä¸ŠçŸ¥è¯†çš„充分利用的é“路。符å·çŸ¥è¯†å¯¹äºŽæœºå™¨å¦ä¹ 模型的é‡è¦ä½œç”¨ä¼šå—到越æ¥è¶Šå¤šçš„关注。这一趋势还å¯ä»¥ä»Žæœºå™¨æ™ºèƒ½è§£å†³é—®é¢˜çš„两个基本模å¼æ–¹é¢åŠ ä»¥è®ºè¿°ã€‚æœºå™¨æ™ºèƒ½çš„å®žçŽ°è·¯å¾„ä¹‹ä¸€æ˜¯ä¹ å¾—æ•°æ®ä¸çš„统计模å¼ï¼Œä»¥è§£å†³ä¸€ç³»åˆ—实际任务。å¦ä¸€ç§æ˜¯ä¸“家系统,专家将知识赋予机器构建专家系统,让机器利用专家知识解决实际问题。
如今,这两ç§æ–¹æ³•æœ‰åˆæµçš„è¶‹åŠ¿ï¼Œæ— è®ºæ˜¯ä¸“å®¶çŸ¥è¯†è¿˜æ˜¯é€šè¿‡å¦ä¹ æ¨¡åž‹ä¹ å¾—çš„çŸ¥è¯†ï¼Œéƒ½å°†æ˜¾å¼åœ°è¡¨è¾¾å¹¶ä¸”沉淀到知识库ä¸ã€‚å†åˆ©ç”¨çŸ¥è¯†å¢žå¼ºçš„机器å¦ä¹ 模型解决实际问题。这ç§çŸ¥è¯†å¢žå¼ºä¸‹çš„å¦ä¹ 模型,å¯ä»¥æ˜¾è‘—é™ä½Žæœºå™¨å¦ä¹ æ¨¡åž‹å¯¹äºŽå¤§æ ·æœ¬çš„ä¾èµ–,æ高å¦ä¹ çš„ç»æµŽæ€§ï¼›æ高机器å¦ä¹ 模型对先验知识的利用率;æå‡æœºå™¨å¦ä¹ 模型的决ç–结果与先验知识的一致性。我个人倾å‘于认为:机器å¦ä¹ 也é¢ä¸´ä¸€æ¬¡å…¨æ–°æœºé‡ã€‚我将其总结为ML+KB=ML2,也就是说机器å¦ä¹ 在知识增强下或许就是下一代机器å¦ä¹ 。
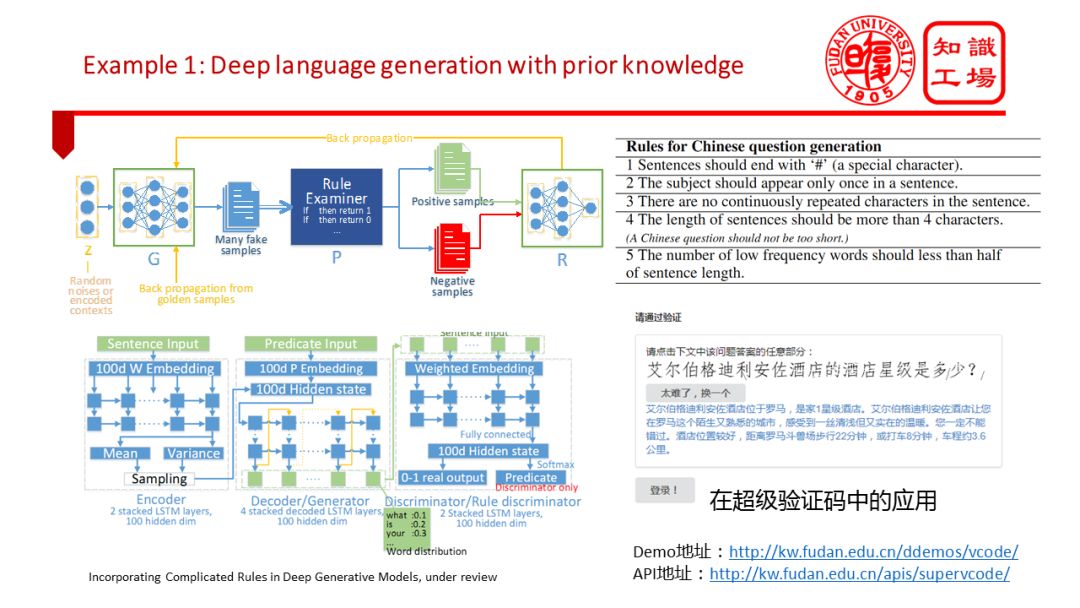
沿ç€ä¸Šé¢çš„æ€è·¯æˆ‘们也åšäº†ä¸€äº›å°è¯•ã€‚在自然è¯è¨€ç”Ÿæˆä»»åŠ¡ä¸ï¼Œæˆ‘们的机器å¦ä¹ 模型,特别是深度生æˆæ¨¡åž‹ä¼šç»å¸¸ç”Ÿæˆå¾ˆå¤šä¸ç¬¦åˆè¯æ³•ã€æˆ–者ä¸ç¬¦åˆè¯ä¹‰çš„å¥å。我们人类显然å¯ä»¥æ€»ç»“出很多è¯æ³•è¯ä¹‰è§„则用于æ述什么是好的自然è¯è¨€è¯å¥ã€‚但是这些知识还很难被机器有效利用。这就需è¦æŠŠè¯æ³•ã€è¯ä¹‰çŸ¥è¯†ç”¨è§„则ã€ç¬¦å·çš„æ–¹å¼è¡¨è¾¾å‡ºæ¥ï¼Œå¹¶æœ‰æ•ˆèžåˆåˆ°æ·±åº¦ç”Ÿæˆæ¨¡åž‹é‡Œé¢ã€‚最近,我们基于对抗生æˆç½‘络åˆæ¥å®žçŽ°äº†è¿™ä¸€ç›®æ ‡ã€‚并将èžåˆäº†å…ˆéªŒçŸ¥è¯†çš„è¯è¨€ç”Ÿæˆæ¨¡åž‹ç”¨äºŽä»ŽçŸ¥è¯†åº“三元组自动生æˆè‡ªç„¶è¯è¨€é—®é¢˜ï¼Œå¹¶å°†è¿™ä¸€æŠ€æœ¯ç”¨äºŽæ–‡æœ¬éªŒè¯ç 。具体技术细节å¯ä»¥å‚考我曾åšè¿‡çš„一个技术报告《未æ¥äººæœºåŒºåˆ†ã€‹ã€‚

知识将æˆä¸ºæ¯”æ•°æ®æ›´ä¸ºé‡è¦çš„资产。å‰å‡ 年大数æ®æ—¶ä»£åˆ°æ¥çš„时候,大家都说“得数æ®è€…得天下â€ã€‚åŽ»å¹´ï¼Œå¾®è½¯ç ”ç©¶é™¢çš„æ²ˆå‘阳åšå£«æ›¾ç»è¯´è¿‡â€œæ‡‚è¯è¨€è€…得天下â€ã€‚而我曾ç»è®ºè¿°è¿‡ï¼Œæœºå™¨è¦æ‡‚è¯è¨€ï¼ŒèƒŒæ™¯çŸ¥è¯†ä¸å¯æˆ–ç¼ºã€‚å› æ¤ï¼Œåœ¨è¿™ä¸ªæ„义下,将是“得知识者得天下â€ã€‚如果说数æ®æ˜¯çŸ³æ²¹ï¼Œé‚£ä¹ˆçŸ¥è¯†å°±å¥½æ¯”是石油的èƒå–物。如果我们åªæ»¡è¶³å–æ•°æ®ç›ˆåˆ©ï¼Œé‚£å°±å¥½æ¯”是直接输出石油在盈利。但是石油的真æ£ä»·å€¼è•´å«äºŽå…¶æ·±åŠ 工的èƒå–物ä¸ã€‚石油èƒå–çš„è¿‡ç¨‹ä¸ŽçŸ¥è¯†åŠ å·¥çš„è¿‡ç¨‹ä¹Ÿæžä¸ºç›¸åƒã€‚都有ç€å¤æ‚æµç¨‹ï¼Œéƒ½æ˜¯å¤§è§„模系统工程。我今天的报告就是在当å‰çš„时代背景下é‡æ–°è§£è¯»å›¾çµå¥–èŽ·å¾—è€…ï¼ŒçŸ¥è¯†å·¥ç¨‹çš„é¼»ç¥–ï¼Œè´¹æ ¹é²å§†æ›¾ç»è¯´è¿‡çš„一å¥è¯â€œknowledge is the power in AIâ€ã€‚è¿™å¥è¯å·²ç»å‡ºçŽ°å‡ å年了,在当今è¯å¢ƒä¸‹éœ€è¦é‡æ–°è§£è¯»ã€‚



最åŽç”¨ä¸‰ä¸ªæ€»ç»“结æŸä»Šå¤©çš„报告。总结1概括了这个报告的主è¦è§‚点。总结2试图å†æ¬¡å¼ºè°ƒæˆ‘的三个观点。总结3想用一å¥è¯å†æ¬¡å¼ºè°ƒçŸ¥è¯†çš„é‡è¦æ€§ã€‚çŸ¥è¯†çš„æ²‰æ·€ä¸Žä¼ æ‰¿é“¸å°±äº†äººç±»æ–‡æ˜Žçš„è¾‰ç…Œï¼Œä¹Ÿå°†æˆä¸ºæœºå™¨æ™ºèƒ½æŒç»æå‡çš„å¿…ç»ä¹‹è·¯ã€‚åªä¸è¿‡åˆ°äº†æœºå™¨èº«ä¸Šï¼ŒçŸ¥è¯†çš„沉淀å˜æˆäº†çŸ¥è¯†çš„è¡¨ç¤ºï¼ŒçŸ¥è¯†çš„ä¼ æ‰¿å˜æˆäº†çŸ¥è¯†çš„åº”ç”¨ã€‚æ‰€ä»¥ï¼ŒçŸ¥è¯†çš„æ²‰æ·€å’Œä¼ æ‰¿ä¸ä»…é“¸å°±äº†äººç±»æ–‡æ˜Žçš„è¾‰ç…Œï¼Œæˆ–è®¸ä¹Ÿå°†é€ å°±æœºå™¨æ™ºèƒ½çš„å…¨æ–°é«˜åº¦ã€‚
Investment Casting, also known as lost wax casting, includes wax pressing, wax repairing, tree formation, paste, wax melting, casting metal liquid and post-treatment processes. Lost wax casting is the process of making a wax mold of the part to be cast, and then coating the wax mold with mud. After the clay mold is dried, melt the wax mold inside in hot water. Melt the wax mold out of the clay mold and then roast into pottery mold. Once roasted. Generally, a casting port is left when the mold is made, and then molten metal is poured into the pouring port. After cooling, the required parts are made.
Investment Casting,Lost Wax Casting,Steel Investment Casting,Stainless Steel Investment Casting
Tianhui Machine Co.,Ltd , https://www.thcastings.com