In most traditional automaTIc speech recogniTIon (ASR) systems, different languages ​​(dialects) are considered independently, and an acoustic model (AM) is generally trained from scratch for each language. This introduces several issues. First, training an acoustic model for a language from scratch requires a large amount of manually labeled data that is not only costly but also takes a lot of time to obtain. This has also led to considerable differences in the quality of acoustic models between data-rich and data-poor languages. This is because for languages ​​with limited data, only small models with low complexity can be estimated. A large number of labeled training data is also an inevitable bottleneck for low-traffic and newly released languages ​​that are difficult to obtain a large number of representative corpora. Second, training an AM independently for each language increases the cumulative training time. This is especially true in DNN-based ASR systems because, as described in Chapter 7, training DNNs is significantly slower than training due to the amount of parameters of the DNN and the backpropagaTIon (BP) algorithm used. Gaussian mixture models (GMM). Third, building separate language models for each language hinders smooth recognition and increases the cost of identifying mixed-language speech. In order to effectively and quickly train accurate acoustic models for a large number of languages, reduce the training cost of acoustic models, and support mixed-language speech recognition (this is a crucial new application scenario, for example, in Hong Kong, English vocabulary is often inserted In Chinese phrases, the research community is increasingly interested in building multilingual ASR systems and reusing multilingual resources.
Although resource constraints (both labeled data and computing power) are a practical reason to study multilingual ASR issues, this is not the only reason. By researching and engineering these technologies, we can also enhance our understanding of the algorithms used and our understanding of the relationships between different languages. There has been a lot of work on multilingual and cross-language ASR (eg [265, 431]). In this chapter, we focus only on the work that uses neural networks.
We will discuss a number of different DNN-based multilingual ASR systems in the following sections. These systems all share the same core idea: a hidden layer of a DNN can be thought of as a stack of feature extractors, and only the output layer directly corresponds to the category we are interested in, as explained in Chapter 9. These feature extractors can be shared across multiple languages, federated with data from multiple languages, and migrated to new (and often resource-poor) languages. By migrating the shared hidden layer to a new language, we can reduce the amount of data required without having to train the entire huge DNN from zero, because only the weight of the output layer of a particular language needs to be retrained.
12.2.1 Cross-language speech recognition based on Tandem or bottleneck features
Most of the early research on multilingual and crosslingual acoustic modeling using neural networks focused on Tandem and bottleneck feature methods [318, 326, 356, 383, 384]. Until the publication of the literature [73, 359], the DNN-HMM hybrid system became an important option for the large vocabulary continuous speech recognition (LVCSR) acoustic model. As described in Chapter 10, in the Tandem or bottleneck feature approach, neural networks can be used to classify single phonetic states or triphone states, and the output or hidden layer excitation of these neural networks can be used as GMM-HMM acoustics. The distinguishing characteristics of the model.
Since both the hidden layer and the output layer of the neural network contain information that classifies the phoneme state in a certain language, and different languages ​​share the phenomenon of sharing similar phonemes, we may use it as a language (called the source language). The Tandem or bottleneck feature extracted from the trained neural network identifies another language (called the target language). Experiments have shown that these migrated features are able to obtain a baseline of a more competitive target language when the tagged data of the target language is small. The neural network used to extract Tandem or bottleneck features can be trained in multiple languages ​​[384], using a different output layer (corresponding to context-independent phonemes) for each language in training, similar to Figure 12.2. In addition, multiple neural networks may be trained by different features, for example, one using perceptual linear prediction features (PLP) [184], while others using frequency domain linear prediction or FDLP [15]. Features extracted from these neural networks can be combined to further improve recognition accuracy.
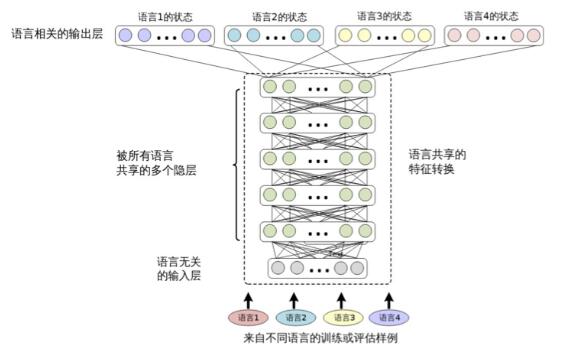
Figure 12.2 Structure of a multilingual deep neural network sharing a hidden layer (similar figure in Huang et al. [204])
Methods based on Tandem or bottleneck features are primarily used for cross-language ASR to improve ASR performance in languages ​​with insufficient data resources. They are rarely used in multilingual ASR. This is because even if the same neural network is used to extract Tandem or bottleneck features, it is often necessary to prepare a completely different GMM-HMM system for each language. However, this limitation may be removed if multiple languages ​​share the same set of phonemes (or context-dependent phoneme states) and decision trees, as done in [265]. The shared set of phonemes can be determined by domain knowledge, such as using the international phonetic alphabet (IPA) [14], or by data-driven methods such as calculating the distance between monophone and triphone states in different languages ​​[431] .
12.2.2 Multi-language deep neural network sharing the hidden layer
Multi-language and cross-language automatic speech recognition is easily implemented through the CD-DNN-HMM framework. Figure 12.2 depicts the structure for multilingual ASR. In [204], this structure is called the multi-language deep neural network (SHL-MDNN) that shares the hidden layer. Because the input and hidden layers are shared by all languages, SHL-MDNN can be identified with this structure. But the output layer is not shared, but each language has its own softmax layer to estimate the posterior probability of the post-cluster state (bound triphone state). The same structure is also independently proposed in the literature [153, 180].
Note that the shared hidden layer in this structure can be thought of as a generic feature transform or a special generic front end. As in the single-language CD-DNN-HMM system, the input to the SHL-MDNN is a long context-sensitive acoustic feature window. However, because shared hidden layers are shared by many languages, some language-dependent feature transformations (such as HLDA) are not available. Fortunately, this limitation does not affect the performance of SHL-MDNN, as any linear transformation can be included by DNN as described in Chapter 9.
The SHL-MDNN described in Figure 12.2 is a special multi-task learning approach [55] that is equivalent to parallel multitasking with shared feature representation. There are several reasons why multitasking is more beneficial than DNN learning. First, multi-task learning is more versatile in feature representation by finding the local bests that are supported by all tasks. Second, it can alleviate the problem of overfitting, because using multiple languages ​​of data can more reliably estimate the shared hidden layer (feature transformation), which is especially helpful for resource-poor tasks. Third, it helps to learn features in parallel. Fourth, it helps to improve the generalization ability of the model, because the current model training involves noise from multiple data sets.
Although SHL-MDNN has these benefits, if we can't train SHL-MDNN correctly, we can't get these benefits. The key to successfully training SHL-MDNN is to train models in all languages ​​simultaneously. This is easy to do when using batch training, such as the L-BFGS or Hessian free [280] algorithm, because all data can be used in each model update. However, if using a random gradient based on small batches of data
(SGD) When training algorithms, it is best to include training data for all languages ​​in each small batch block. This can be efficiently accomplished by randomizing the data to include a list of training audio samples for all languages ​​before providing the data to the DNN training tool.
Another training method is proposed in [153]. In this approach, all hidden layers are first trained using the unsupervised DBN pre-training approach mentioned in Chapter 5. Then a language is selected, randomly activating the softmax layer corresponding to the language and adding it to the network. This softmax layer and the entire SHL-MDNN are tuned using data from this language. After the adjustment, the softmax layer is replaced by a randomly initialized softmax corresponding to the next language, and the network is adjusted with the data of that language. This process is repeated for all languages. One possible problem with this linguistic sequence training approach is that it leads to biased estimates and performance is degraded compared to simultaneous training.
SHL-MDNN can be pre-trained using the generated or discerning pre-training techniques described in Chapter 5. The SHL-MDNN adjustment can use the traditional backpropagation (BP) algorithm. However, because each language uses a different softmax layer, the algorithm requires some fine-tuning. However, when a training sample is given to the SHL-MDNN trainer, only the shared hidden layer and the softmax layer of the specified language are updated. The other softmax layers remain unchanged.
After training, SHL-MDNN can be used to identify the language used in any training. Because multiple languages ​​can be decoded simultaneously in this unified structure, SHL-MDNN makes large vocabulary continuous language recognition tasks easy and efficient. As shown in Figure 12.3, it is easy to add a new language to SHL-MDNN. This only requires adding a new softmax layer to the existing SHL-MDNN and training the new softmax layer with the new language.
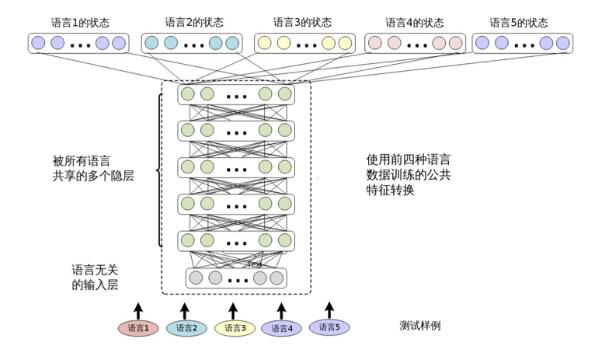
Figure 12.3 SHL-MDNN trained in four languages ​​supports the fifth language
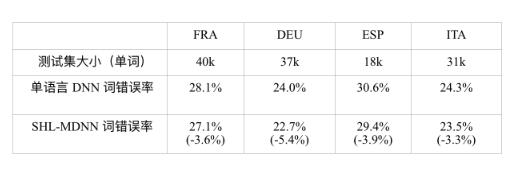
By sharing the hidden layer and joint training strategies in SHL-MDNN, SHL-MDNN can improve the recognition accuracy of all decodable languages ​​compared to single-language DNNs that are only trained in a single language. Microsoft conducted an internal evaluation of SHL-MDNN [204]. The SHL-MDNN in the experiment has 5 hidden layers with 2048 neurons per layer. The input to the DNN is a 13-dimensional MFCC feature with 11 (5-1-5) frames with first and second order differences. Training was conducted using 138 hours of French (FRA), 195 hours of German (DEU), 63 hours of Spanish (ESP), and 63 hours of Italian (ITA) data. For a language, the output layer contains 1800 triphone clustering states (ie, output categories) that are determined by the GMM-HMM system trained with the same training set and Maximum Likelihood Estimation (MLE). The SHL-MDNN is initialized using an unsupervised DBN pre-training method, and then the BP algorithm is used to adjust the model using the clustered state aligned by the MLE model. The trained DNN is then used in the CD-DNN-HMM framework introduced in Chapter 6.
Table 12.1 compares the word error rate (WER) of a single-language DNN and a multi-language DNN sharing a hidden layer. The single-language DNN uses only data training in the specified language and tests with the test set of this language. The hidden layer of SHL-MDNN is Data training in all four languages ​​is available. It can be observed from Table 12.1 that SHL-MDNN is 3% to 5% less WER than single-language DNN in all languages. We believe that the upgrade from SHL-MDNN is due to cross-language knowledge. Even with FRA and DEU with more than 100 hours of training data, SHL-MDNN is still improving.
Table 12.1 compares the word error rate (WER) of a multilingual DNN with a single-language DNN and a shared hidden layer; the relative reduction in WER is in parentheses.
12.2.3 Cross-language model migration
The shared hidden layer extracted from the multilingual DNN can be regarded as a feature extraction module jointly trained by multiple source languages. Therefore, they are rich in information identifying speech categories in multiple languages ​​and can recognize phonemes in new languages.
The process of cross-language model migration is simple. We only extract the shared hidden layer of SHL-MDNN and add a new softmax layer on it, as shown in Figure 12.4. The output node of the softmax layer corresponds to the state after the target language is clustered. Then we fixed the hidden layer and trained the softmax layer with the training data of the target language. If there is enough training data available, you can get additional performance gains by further tweaking the entire network.
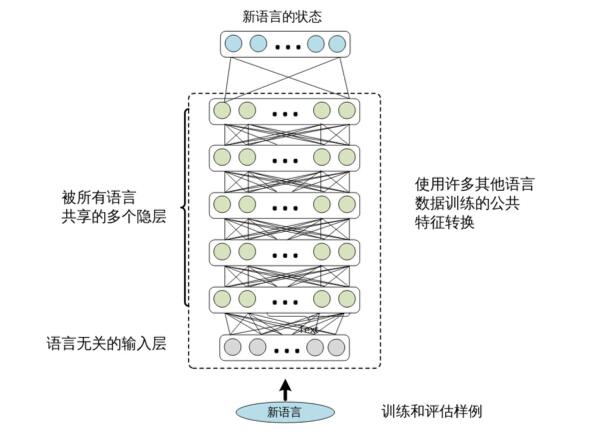
Figure 12.4 Cross-language migration. The hidden layer is borrowed from the multilingual DNN, while the softmax layer needs to be trained with the data in the target language.
In order to evaluate the effects of cross-language model migration, a series of experiments were done in [204]. In these experiments, two different languages ​​were used as the target language: American English (ENU), which is similar to the European language that trained SHL-MDNN in Section 12.2.2, and Mandarin Chinese (CHN), which is far from the European language. The ENU test set includes 2286
In the sentence (or 18,000 words), the CHN test set includes 10510 sentences (or 40,000 characters).
Hidden layer mobility
The first question is whether the hidden layer can be migrated to other languages. To answer this question, we assume that the 9-hour American English training data (55737 sentences) can build an ENU ASR system. Table 12.2 summarizes the experimental results. The baseline DNN uses only the 9-hour ENU training set, which achieves 30.9% of the WER on the ENU test set. Another way is to borrow hidden layers (feature transformations) learned from other languages. In this experiment, a single-language DNN was trained by 138 hours of French data. The hidden layer of this DNN is then extracted and reused in the US English DNN. If the hidden layer is fixed, only the 9-hour American English data is used to train the softmax layer corresponding to the ENU, and a 2.6% WER reduction from the baseline DNN can be obtained (30.9%→27.3%). If the entire French DNN is retrained with 9 hours of US English data, a 30.6% WER can be obtained, which is slightly better than the 30.9% baseline WER. These results illustrate that the feature transformation represented by the hidden layer of the French DNN can be effectively migrated to identify American English speech.
Table 12.2 Comparison of word error rates on ENU test sets with and without hidden layer networks migrated from French DNN
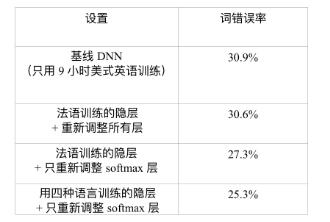
In addition, if the shared hidden layer of SHL-MDNN described in Section 12.2.2 is extracted and used in the US English DNN, an additional 2.0% WER reduction (27.3%→25.3%) can be obtained. This shows that when constructing the American English DNN, the hidden layer extracted from SHL-MDNN is more efficient than the hidden layer extracted from the separate French DNN. In summary, a 4.6% (or relative 18.1%) WER reduction can be achieved by using a cross-language model migration relative to the baseline DNN.
Target language training set size
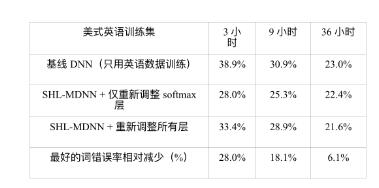
The second question is how the size of the training set of the target language affects the performance of multilingual DNN cross-language model migration. To answer this question, Huang et al. did some experiments, assuming that 3, 9 and 36 hours of English (target language) training data were available. Table 12.3 in [204] summarizes the experimental results. It can be observed from the table that the DNN using the migration hidden layer is always better than the baseline DNN without the cross-language model migration. We can also observe that the optimal strategy will be different when different sizes of target language data are available. When the training data for the target language is less than 10 hours, the best strategy is to train only the new softmax layer. When the data is 3 hours and 9 hours respectively, you can see a relative reduction of 28.0% and 18.1% WER. However, when the training data is sufficient, further training of the entire DNN can result in additional error reduction. For example, when 36 hours of US English speech data is available, we observed an additional 0.8% WER reduction (22.4%→21.6%) by training all layers.
Table 12.3 compares the effect of the target language training set size on the word error rate (WER) when the hidden layer is migrated from SHL-MDNN.
The migration from European to Mandarin is effective
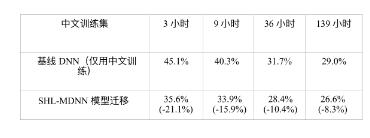
The third question is whether the effect of the cross-language model migration approach is sensitive to the similarity between the source and target languages. To answer this question, Huang et al. [204] used Mandarin Chinese (CHN), which is very different from the European language that trained SHL-MDNN, as the target language. Table 12.4 in [204] lists the word error rate (CER) for baseline DNN and multi-language enhanced DNN for different Chinese training set sizes. When the data is less than 9 hours, only the softmax layer is trained; when the Chinese data is more than 10 hours, all layers are further adjusted. We can see that all CERs are reduced by using the migration hidden layer. Even with 139 hours of CHN training data available, we can still get a relative reduction of 8.3% CER from SHL-MDNN. In addition, with only 36 hours of Chinese data, we can get 28.4% of CERs on the test set by migrating the shared hidden layer of SHL-MDNN. This is better than a baseline DNN using 139 hours of Chinese training data to get 29% CER, saving more than 100 hours of Chinese annotation.
Table 12.4 The cross-language model migration effect of CHN, measured by the word error rate (CER) reduction; the relative decrease in CER in parentheses.
The need to use annotation information
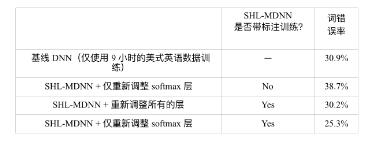
The fourth question is whether features extracted through unsupervised learning can perform as well as supervised learning on classification tasks. If the answer is yes, this approach has a significant advantage because it is much easier to get unlabeled voice data than the labeled voice data. This section reveals that labeling information is important for efficient learning of shared representations of multilingual data. Based on the results in [204], Table 12.5 compares the two systems with and without annotation information when training the shared hidden layer. It can be seen from Table 12.5 that only the pre-trained multi-language deep neural network is used, and then the ENU data is used to adapt to the method of learning the entire network, with only a small performance improvement (30.9%→30.2%). This improvement is significantly less than the improvement gained when using annotation information.
(30.9%→25.3%). These results clearly show that label data is more valuable than unlabeled data, and that the use of label information is important when learning efficient features from multilingual data.
Table 12.5 compares features learned from multilingual data with and without annotation information on ENU data.
Shenzhen Ruidian Technology CO., Ltd , https://www.szwisonen.com