Editor's note: Following OpenAI's release of Dota2's team battle AI, DeepMind today also released its latest research, some artificial intelligence robots that can collaborate with each other or with human players. The following is Lunzhi's compilation of DeepMind's blog post.
In game projects, it is very important for AI to master strategy, understand tactics, and collaborate in teams. Now that reinforcement learning has been developed, our agents have reached a human level in the "Capture the Flag" game of "Thor's Hammer III: Arena", and they have demonstrated a high level of teamwork.
The Capture the Flag mode (CTF) of "Quoroh III: Arena" is a multiplayer game displayed from a first-person perspective. The participants are divided into two groups, the red team and the blue team. The goal of each team member is to capture the opponent's flag and bring it back to their base, while protecting their own flag. 1 point for killing the opponent, 1 point deducted for your own abnormal death, 3 points for capturing the opponent's flag, 2 points for killing the flag capturer, 1 point for regaining your own flag, and successfully capturing a flag (send the flag back to your own Base) 5 points. The side with more flags within five minutes wins.
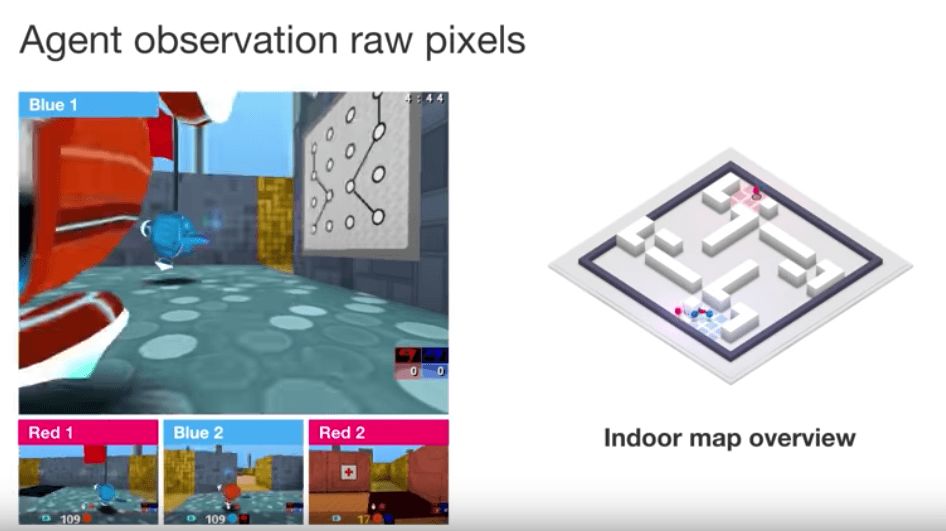

The four agents we trained competed in both indoor and outdoor environments, and gradually cultivated to a level capable of capturing the flag
For humans, each individual has its own goals and actions, but we can still show collective wisdom in teams and organizations. We call this setting "multi-agent learning": multiple agents must Act independently, but learn to interact and cooperate with other agents. This question is very difficult because the environment is constantly changing.
In order to study this issue, we take various 3D first-person video games as the research object. They represent most game formats and reflect the strategies of various players because they include their understanding of the game and hand-eye coordination. And the team plan. The challenge our agent faces is to learn directly from the original pixels to output actions.
In the experiment, the game "Quaker III: Arena" we chose is the basis of many first-person role games. We train the agent to learn and act like a single player, but we still have to cooperate between teams to fight the enemy together. .
From a multi-agent perspective, CTF requires players to be able to cooperate perfectly with their teammates, but also to fight against the enemy, regardless of their style, to maintain a level of stability.
In order to make this process more interesting, we also designed a variant of CTF, in which the flat map is different for each field. As a result, our agent is forced to learn a "general strategy" instead of relying on the memory of the map to win. In addition, in order to evaluate the game field, our agents feel the CTF environment in a human way: they observe a series of pixel images and actions through a virtual game controller.

The CTF environment is constantly updated, so the agent must adapt to unfamiliar maps
Our agents must learn from scratch how to observe terrain, actions, cooperation, and competition in an unfamiliar environment, all of which come from a single reinforcement signal for each game: whether or not their team wins. This is a challenging learning problem, and the solution is based on three basic problems of reinforcement learning:
In contrast to training a single agent, we are training multiple agents, which learn through interaction with various teammates and opponents.
Each agent in the team learns from its own internal reward signal, allowing the agent to generate its own internal goals, such as obtaining a flag. The two-stage optimization process optimizes the internal rewards of the agent, and at the same time uses the reinforcement learning of internal rewards to learn the agent's strategy.
Agents will be trained at two speeds, fast and slow, which will improve their ability to use memory and generate continuous actions.
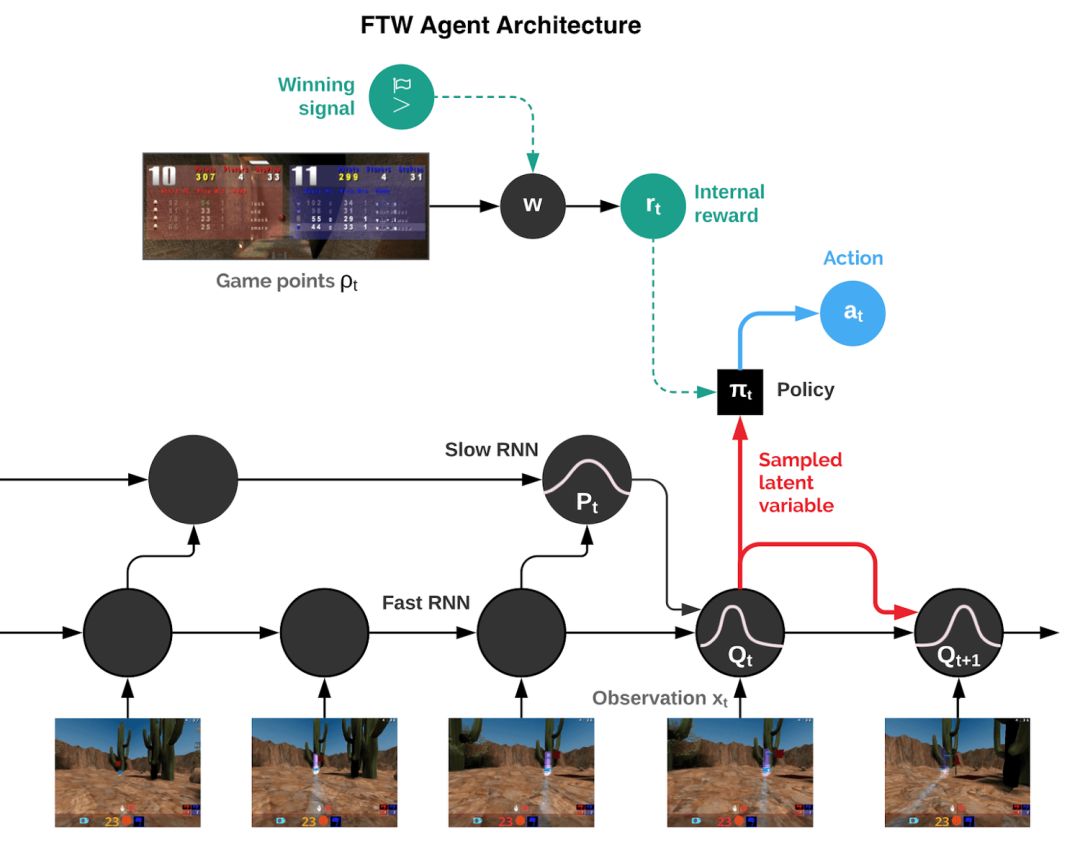
The finally trained agent (FTW) showed a very high level in playing CTF. What is important is that the agent behaves stably under various maps and the number of players. Whether in outdoor mode or indoor mode, or in competitions with human participation, FTW performed well.

We organized a tournament in which 40 human players were randomly assigned to the game by combining humans and agents.
After learning, the FTW agent is more powerful than the benchmark method, and at the same time surpasses the win rate of human players. In fact, in the evaluation of participants, the cooperative ability of agents is stronger than that of humans.
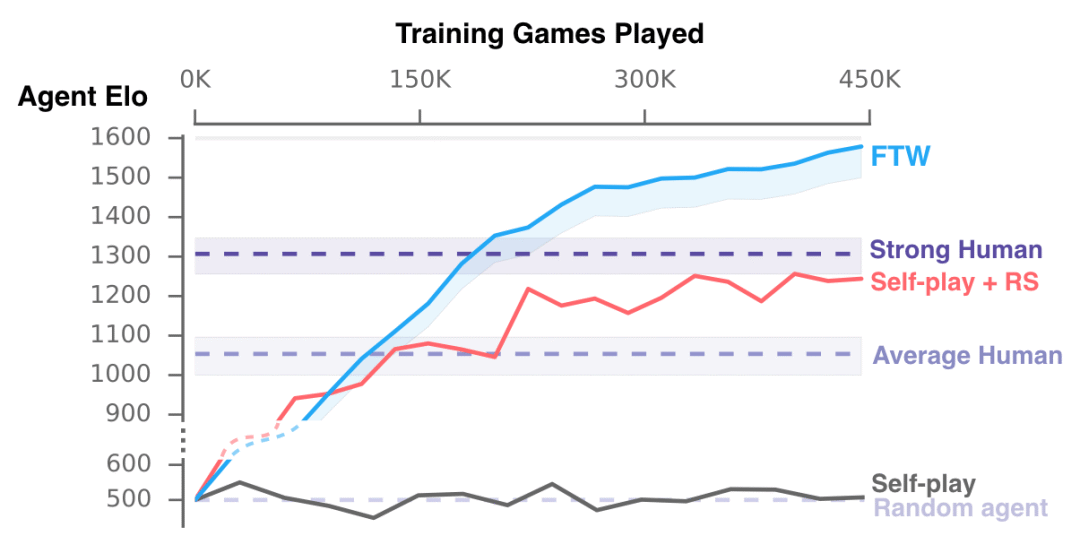
The performance of the agent in training compared with humans
Understand the internal mechanism of the agent
In order to understand how the agent represents the game state, we looked at the activity form of the agent's neural network. The following chart shows the situation during the game. The dense dots are divided into different colors according to the state of the CTF in the game. According to the color, you can judge: In which room the agent is? What is the status of the flag? Which teammate or opponent can you see? By observing the points with the same color, we find that the actions of agents in similar states are also similar.

Each colored dot represents the state and position of various agents in the game
We will not tell agents the rules of the game, but let them learn the basic concepts themselves. In fact, we can find neurons that specifically encode important game states, such as neurons that are active when the flag is taken away, or neurons that are active when a teammate gets the flag. If you want to know more details about the agent, please check the original paper.
Apart from these various representations, how does the agent actually work? First, we noticed that the agent’s response time is very fast, and it also has precise markers. But when they artificially reduce their accuracy and response time, we see only one factor leading to success.
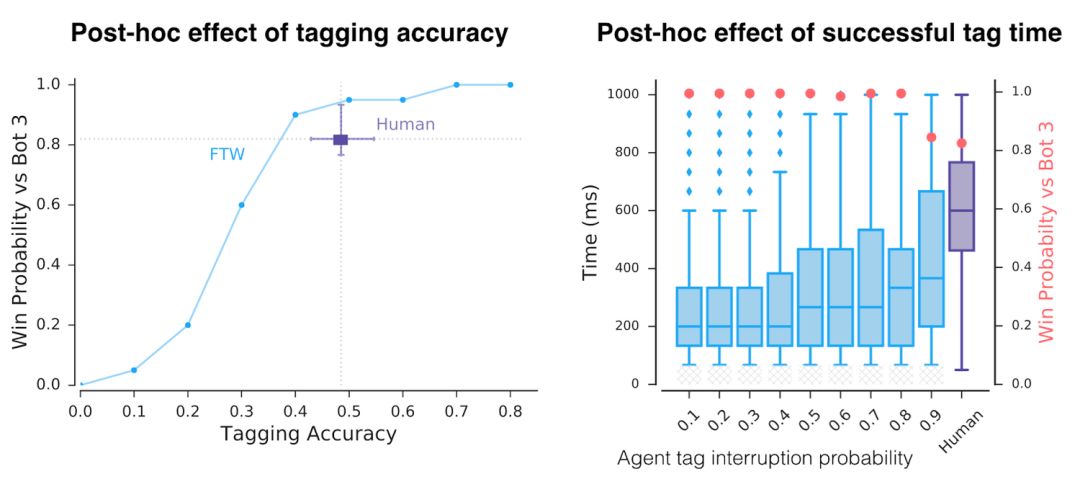
The accuracy and reaction time of the agent is higher than that of the human
Through unsupervised learning, we created the original actions of the agent, and found that the agent is actually imitating human behavior, such as following teammates or "setting up camp" at the opponent's base. These actions are derived through reinforcement learning and evolution during training.

Conclusion
Recently, artificial intelligence has made considerable progress in complex games such as StarCraft II and Dota 2. Although the focus of this project is on "capture the flag" games, the contributions made are universal. The researchers said, They are very happy to see other researchers applying this technology in different environments. In the future, they will improve the current reinforcement learning and training methods based on multiple agents. Overall, this work highlights the potential of multi-agent training and helps them cooperate with humans.
The latest Windows has multiple versions, including Basic, Home, and Ultimate. Windows has developed from a simple GUI to a typical operating system with its own file format and drivers, and has actually become the most user-friendly operating system. Windows has added the Multiple Desktops feature. This function allows users to use multiple desktop environments under the same operating system, that is, users can switch between different desktop environments according to their needs. It can be said that on the tablet platform, the Windows operating system has a good foundation.
Windows Tablet,New Windows Tablet,Tablet Windows
Jingjiang Gisen Technology Co.,Ltd , https://www.jsgisengroup.com