The human driver will roughly assess his or her next position based on the trajectory of the pedestrian, and then calculate the safe space (path planning) according to the speed of the bus. The bus driver is best at this. Driverless cars can do the same. It should be noted that this is the tracking and prediction of trajectories of multiple moving objects, which is much more difficult than a single object. This is the perception of the environment and it is also the most difficult technology for driverless cars.
Introduce context-aware content today. Environmental awareness is also referred to as MODAT (Moving Object Detection and Tracking).
The four core technologies of automatic driving are environment perception, precise positioning, path planning, and line control execution. Environmental perception is the most studied part of it, but visual perception based on the environment can not meet the autonomous driving requirements of unmanned vehicles. The road conditions faced by an actual driverless car are far more complex than those of a laboratory simulation or test track. This requires the establishment of a large number of mathematical equations. Good planning must establish a deep understanding of the surrounding environment, especially the dynamic environment.
Environmental perception mainly includes three aspects: road surface, static objects and dynamic objects. For a dynamic object, it is necessary to not only detect the trajectory but also track its trajectory and predict the trajectory (position) of the object according to the tracking result. This is essential in the urban areas, especially in the urban areas of China. The most typical scene is Beijing Wudaokou: If you stop when you see a pedestrian, you will never be able to pass through Wudaokou. Pedestrians will almost never walk past the car. The human driver will roughly assess his or her next position based on the trajectory of the pedestrian, and then calculate the safe space (path planning) according to the speed of the bus. The bus driver is best at this. Driverless cars can do the same. It should be noted that this is the tracking and prediction of trajectories of multiple moving objects, which is much more difficult than a single object. This is MODAT (Moving Object Detection and Tracking). It is also the most difficult technology for driverless cars.
The following figure is a typical environment awareness framework for driverless cars:
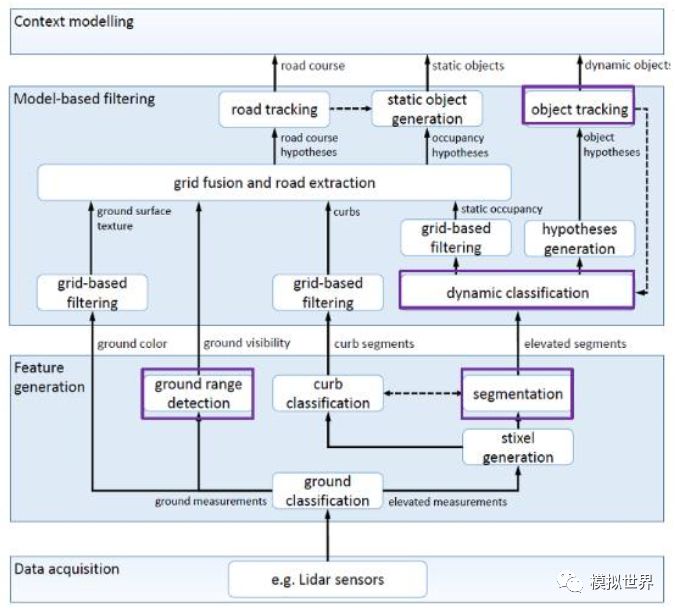
This is based on the Lidar's environment-aware model. At present, there are many more people engaged in the research of visual environment perception models than Lidar. Unfortunately, in the case of driverless cars, the vision is certainly not enough. In the long run, Lidar and millimeter-wave radar, combined with a comprehensive vision-aware solution, can truly be unmanned.
Let us look at the development of computer vision. The history of neural networks can be traced back to the 1940s and once it became popular in the 1980s and 1990s. The neural network attempts to solve various machine learning problems by simulating the mechanism of brain cognition. In 1986, Rumelhart, Hinton and Williams published the famous back-propagation algorithm in Nature to train neural networks. It is still widely used today.
However, deep learning has been quiet for a long time since the 1980s. The neural network has a large number of parameters, and the fitting problem often occurs. That is, the accuracy is often high on the training set, but it is poor on the test set. This is partly due to the small scale of the training data set at the time and the limited computing resources, even if it takes a long time to train a smaller network. Compared with other models, neural networks do not have obvious advantages in the recognition accuracy and are difficult to train.
Therefore, more scholars have begun to use classifiers such as Support Vector Machine (SVM), Boosting, and Nearest Neighbor. These classifiers can be modeled using a neural network with one or two hidden layers and are therefore referred to as shallow machine learning models. They no longer simulate the cognitive mechanism of the brain; instead, different systems are designed for different tasks and different hand-designed features are used. For example, Gaussian mixture model and hidden Markov model are used for speech recognition. SIFT features are used for object recognition, LBP features are used for face recognition, and HOG features are used for pedestrian detection.
Since 2006, thanks to the pursuit of performance by computer game enthusiasts, GPU performance has grown rapidly. At the same time, the Internet is very easy to access massive training data. The combination of the two, deep learning or neural networks rejuvenated the second spring. In 2012, Hinton's research team used deep learning to win the ImageNet image classification competition. Since then, deep learning has begun to sweep the globe.
The biggest difference between deep learning and traditional pattern recognition methods is that it automatically learns features from big data, rather than using hand-designed features. Good features can greatly improve the performance of the pattern recognition system. In the various applications of pattern recognition in the past decades, the characteristics of manual design are dominant. It relies mainly on the prior knowledge of the designer and it is difficult to take advantage of big data. Due to the manual adjustment of parameters, only a small number of parameters are allowed in the design of features. Deep learning can automatically learn the representation of features from big data, which can contain thousands of parameters. Manually designing effective features is a rather lengthy process. Recalling the history of the development of computer vision, it often takes five to ten years before a widely recognized good feature emerges. Deep learning can quickly learn new effective feature representations from training data for new applications.
A pattern recognition system consists of two main components: feature and classifier. The two are closely related to each other. In the traditional method, their optimization is separate. In the framework of neural networks, feature representations and classifiers are jointly optimized. Both are inseparable. The detection and recognition of deep learning is one and it is difficult to separate. This is true when training data from the very beginning. Semantic-level annotation is the most obvious feature of training data. Absolute unsupervised deep learning does not exist, even if weak supervision of deep learning is rare. Therefore, it is difficult to visually identify and detect obstacles in real time. The laser radar cloud point is good at detecting and detecting 3D contours of obstacles. The relative depth learning of the algorithm is much simpler and it is easy to do real-time. Lidar has intensity scanning imaging. In other words, laser radar can know the density of obstacles, so it can easily distinguish grassland, trees, buildings, leaves, trunks, street lamps, concrete, and vehicles. This semantic recognition is very simple and only needs to be based on the intensity spectrum map. Visually speaking, accurate identification is very time-consuming and not reliable.
The most deadly disadvantage of visual depth learning is that it is extremely weak in video analytics. The video that a driverless car faces is not a static image. Video analysis is exactly what Lidar does. Visual deep learning is at the initial stage of video analysis. It describes the static image features of video and can use the depth model learned from ImageNet. The difficulty is how to describe dynamic features. In previous visual methods, the description of dynamic features often relied on optical flow estimation, tracking of key points, and dynamic textures. How to embed this information in the depth model is a difficult point. The most straightforward approach is to treat the video as a three-dimensional image, apply the convolutional network directly, and learn three-dimensional filters at each layer. However, this thinking obviously does not take into account the differences in time dimension and space dimension. Another simple but more effective idea is to calculate the optical flow field through preprocessing as an input channel to the convolutional network. There are also researches that use deep encoders to extract dynamic textures in a non-linear manner, whereas most of the traditional methods use linear dynamic system modeling.
The optical flow only calculates the motion of two adjacent frames, and the time information is also insufficiently expressed. Two-stream can only be considered a transitional method. At present, CNN engages in airspace and RNN has reached consensus in the time domain, especially the introduction of LSTM and GRU structures. The RNN does not perform well on motion recognition, and certain single frames can identify motions. In addition to the large structure, some auxiliary models, such as the visual hard/softattention model, and the compressed neural network on ICLR2016 will affect the future deep learning video processing.
At present, deep learning is not as good as manual features in video analysis. The disadvantages of manual features, as already mentioned, are low accuracy and high false alarm rates. The future may be difficult to improve.
MODAT must first analyze the video and calculate the ground plane in real time. This is very easy for a point cloud-based laser radar, and it is difficult for the visual sense.
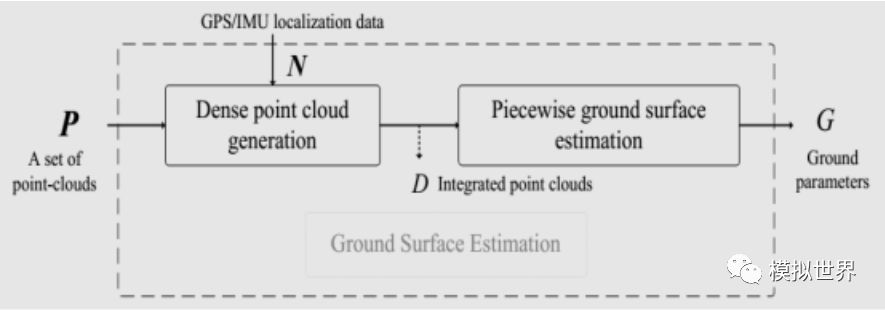
The real ground plane is calculated using the piecewise plane fitting and the RANSAC algorithm. Actually relying on laser radar's intensity scan imaging, it can also obtain an accurate ground plane. This is also the main reason for the use of laser radar in remote sensing. It can exclude vegetation disturbances, obtain accurate topographic maps, and provide a ground reference plane.
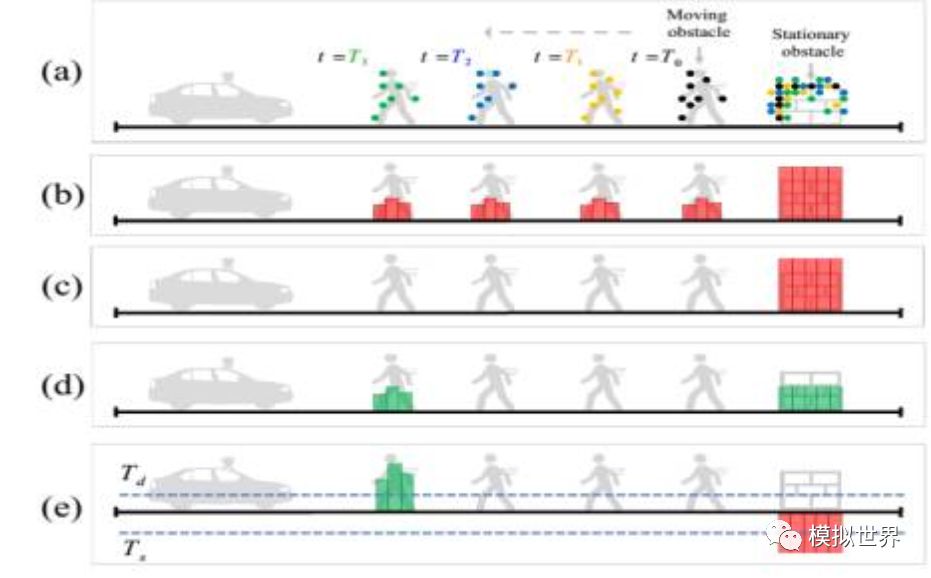
The VOXEL GRID filter was used to separate the mobile still bodies. Black-brown, blue-green and green were the assumptions of each time period that the laser radar launched onto the pedestrian. Compared with dynamic objects, static objects capture more natural cloud points.
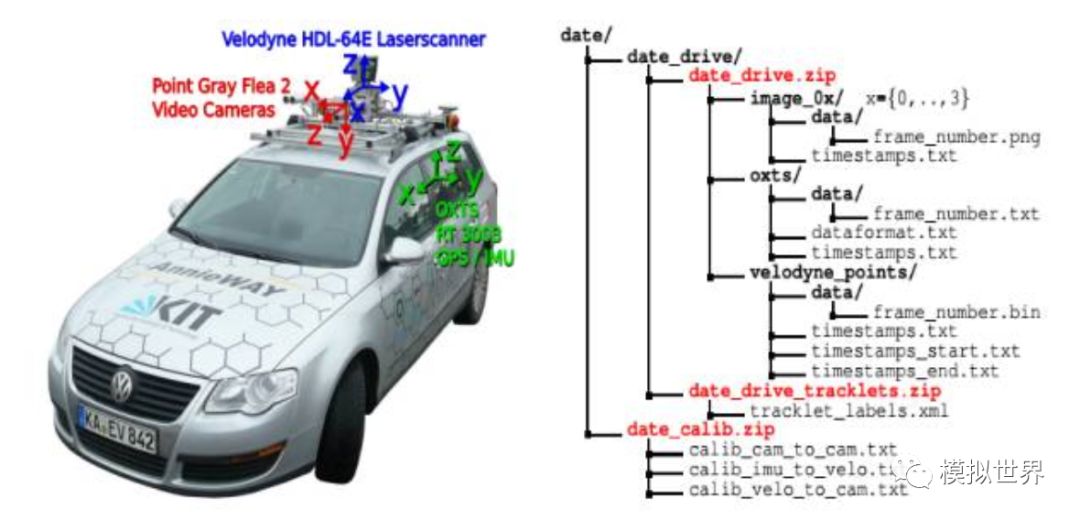
On the left is the collection vehicle of the authoritative Kitti data set, which is well-known in the deep learning field. On the right is the data format and content of the data set. Kitti has a description of its Ground Truth:
To generate 3Dobject ground-truth we hired a set of annotators, and asked them to assigntracklets in the form of 3D bounding boxes to objects such as cars, vans, trucks, trams, pedestrians and cyclists. Unlike most existing benchmarks, we donot rely on Online crowd-sourcing to perform the labeling. Towards this goal, we create a special purpose labeling tool, which displays 3D laser points aswell as the camera images to increase the quality of the annotations.
Kitti said clearly that the labeling of training data is not an artificial crowdsourcing, but it has created an automatic labeling software that displays 3D laser cloud points as optical images to improve the quality of labels. Very simply, Lidar is the standard for 3D Object Detection, and even if visual deep learning is powerful, there is always a gap with Lidar.
Let's talk about Stiexel (sticks above the ground in the image), which is generally called stick pixels. This is a fast real-time detection method for obstacles introduced by Mercedes-Benz and Professor Hern Ìan Badino at the University of Frankfurt in 2008. It is particularly suitable for pedestrian detection. Can do 150 or 200 frames per second, which is the dual purpose of Mercedes-Benz and BMW. Hern Ìan Badino was later swept away by the robotics lab at Cameron University. Uber's unmanned vehicle was mainly based on the Robot Lab at Cameron University. The core of Stixel is to calculate the top and bottom edge of the rod and the binocular parallax, and build a Stixel to accurately and quickly detect obstacles, especially pedestrians. This is the main reason for Mercedes-Benz BMW's large-scale use of dual purposes. Compared to single-purpose pedestrian identification, binocular Stixel has the advantage of rolling.
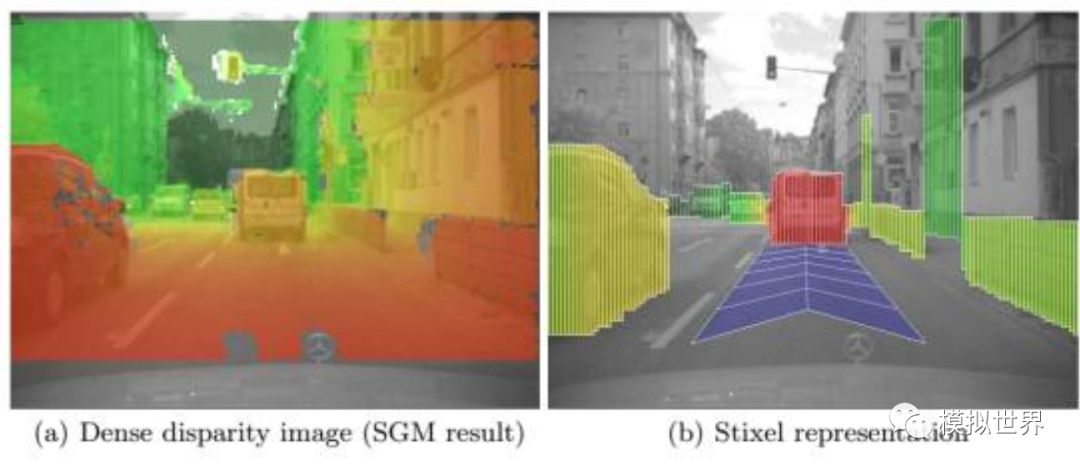
With Lidar, it is easier to obtain the corresponding 3D distance information, and it is also more accurate. Therefore, it is faster and more accurate to establish Steixel.
It's time to talk about Tracking. Now many people confuse tracking with computer target tracking. The former is more biased toward mathematics and is an algorithm that models the temporal changes in the state space and predicts the state of the next moment. For example Kalman filter, particle filter and so on. The latter is biased towards the application, given the frame of an object in the first frame of the video, and the position of the object in the subsequent frame is given by the algorithm. Initially it was to solve the problem that the detection algorithm was slower, and later it gradually became itself. Because it becomes an application problem, the algorithm is more complex and usually consists of several modules, including mathematical tracking algorithms, extraction features, and online classifiers.
After the self-contained system, the target tracking actually becomes the problem of using the object state (rotation angle, scale) of the previous frame to constrain (prune) the object detection of the next frame. It changed back to the object detection algorithm, but artificially stripped the first frame from the target frame. While all parties are struggling to establish an end-to-end system, target tracking only examines one sub-problem, selectively ignoring the question of "how the box in the first frame came from."
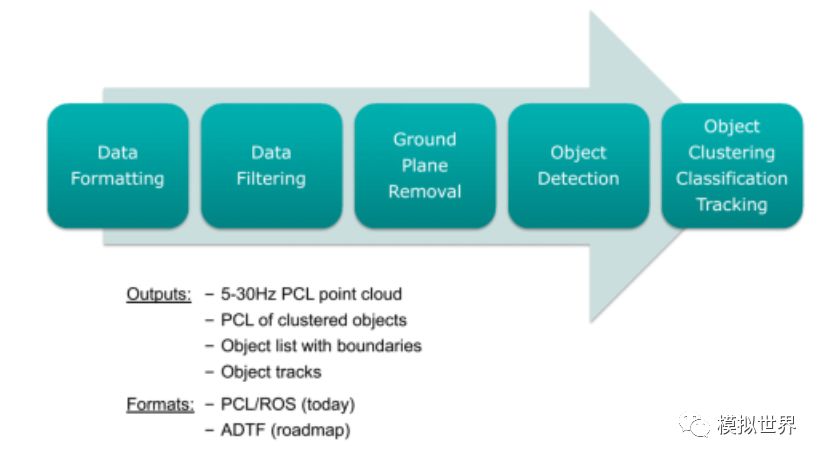
Lidar's Tracking is easy to do. Take IBEO as an example, each laser radar from IBEO comes with a software called IBEOObject Tracking. This is a Cayman filter-based technology that can track up to 65 targets in real time. In real time, this is something that the visual class simply can't think of. Quanergy also has similar software called 3DPerception.
Fiber Optic Adapter / Fiber Optic Coupler
Fiber To Ethernet Converter,Optical To Ethernet Converter,Optical Fiber To Ethernet Converter,Fiber Optic To Ethernet Converter Price
Ningbo Fengwei Communication Technology Co., Ltd , https://www.fengweicommunication.com