A series of machine learning optimized chips are expected to begin shipping in the next few months, but it will take some time for data centers to decide whether these new accelerators are worth adopting and whether they can really improve performance.
There are a large number of reports that custom chips designed for machine learning will provide 100 times the performance of existing options, but their function in actual tests for demanding commercial purposes has not been proven. Data centers are the most conservative of new technologies. One of the adopters. However, well-known startups such as Graphcore, Habana, ThinCI and WaveCompuTIng said they have already provided early chips to customers for testing. But no company has started shipping or even showing these chips.
There are two main markets for these new devices. Neural networks in machine learning divide data into two main stages: training and inference, and use different chips in each stage. Although the neural network itself usually resides in the data center during the training phase, it may have edge components used in the inference phase. The question now is what type of chip and what configuration can produce the fastest and most efficient deep learning.
Compared to a few years ago, FPGA settings are now used for training less frequently, but they are used much more frequently for everything else, and they are likely to continue to grow next year. Even if about 50 startups dedicated to the iterative development of neural network optimized processors have delivered finished products today, it will take 9 to 18 months for the production process of any sizeable data center.
McGregor said: "No one will buy an off-the-shelf data center and put it on a production machine." "You must ensure that it meets reliability and performance requirements before you can deploy it all."
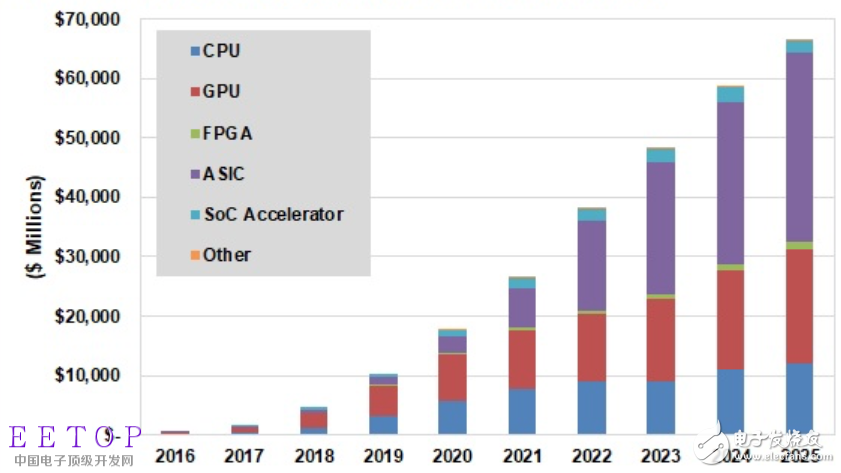
Figure 1: Proportion of different types of deep learning chips
There are still opportunities for new architectures and microarchitectures. ML workloads are rapidly expanding. An OpenAI report in May showed that the computing power used for the largest AI/ML training doubled every 3.5 months. Since 2012, the total computing power has increased by 300,000 times. In contrast, according to Moore's Law, the available resources double every 18 months, and the final total capacity only increases by 12 times.
Open.AI pointed out that the systems used for the largest training scales (some of which take days or weeks to complete) need to spend millions of dollars to purchase, but it expects that most of the funds used for machine learning hardware will be used reasoning.
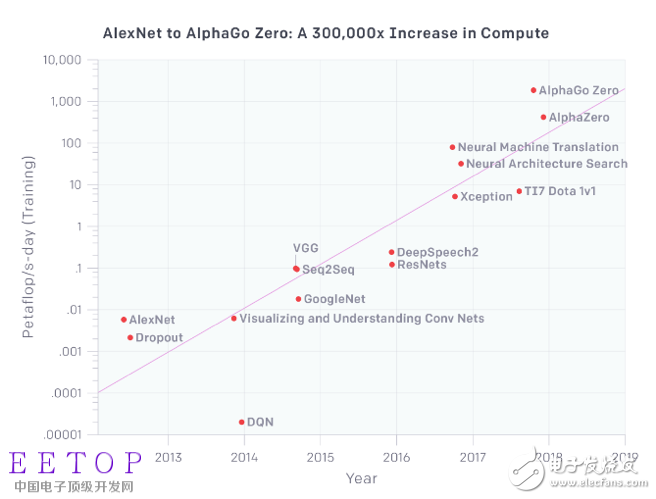
Figure 2: Computing demand is increasing
This is a huge new opportunity. TracTIca predicted in a report on May 30 that by 2025, the market size of deep learning chipsets will increase from $1.6 billion in 2017 to $66.3 billion, including CPUs, GPUs, FPGAs, ASICs, and SoC accelerators. And other chipsets. A large part of this will come from non-chip companies, which are releasing their own deep learning accelerator chipsets. Google’s TPU does just that, and industry insiders say that Amazon and Facebook are following the same path.
McGregor said that the shift is now mainly to SoC rather than independent components, and the diversity of strategies and packaging of SoC, ASIC and FPGA vendors is increasing.
Xilinx, Inetel and other companies are trying to expand the scale of FPGAs by adding processors and other components to the FPGA array. Others, such as FlexLogix, Achronix, and Menta, embed FPGA resources in small blocks close to specific functional areas of the SoC, and rely on high-bandwidth interconnects to maintain data mobility and high performance.
McGregor said: "You can use FPGAs wherever you want programmable I/O. People will use them for inference and sometimes for training, but you will find that they will be used more for processing big data tasks. Rather than training, this requires a lot of matrix multiplication and is more suitable for GPUs."
However, GPU is not an endangered species. According to MoorInsights & Strategy analyst Karl Freund in a blog post.
Nvidia announced earlier this month the statement of the NVIDIA TensorRT super-size inference platform, which includes TeslaT4GPU that provides 65TFLOPS for training and 260 trillion 4-bit integer operations per second (TOPS) inference-enough to handle 60 video streams at the same time. It is 30 frames per second. It includes 320 "TuringTensorcores", optimized for integer calculations required for inference.
New architecture
Graphcore is one of the most famous start-up companies. It is developing a 23.6 billion transistor "intelligent processing unit" (IPU) with 300MB on-chip memory, 1216 cores, each core can reach 11GFlops, and the internal memory bandwidth is 30TB/ s. Two of them use a single PCIe card, and each card is designed to save the entire neural network model on a single chip.
GraphCore's upcoming chip is based on a graphics architecture that relies on its software to convert data into vertices, where digital inputs, functions (addition, subtraction, multiplication, division) and results applied to them are individually defined and can be processed in parallel . Several other ML startups also use similar methods.
WaveCompuTIng did not disclose when it will ship, but revealed more information about its architecture at the artificial intelligence hardware conference last week. The company plans to sell systems instead of chips or circuit boards, using 16nm processors with 15Gbyte/sec ports and HMC memory and interconnects. This option is designed to quickly push graphics through the processor cluster without the need to send data through the processor. A PCIe bus is the bottleneck. The company is exploring switching to HBM memory for faster throughput.
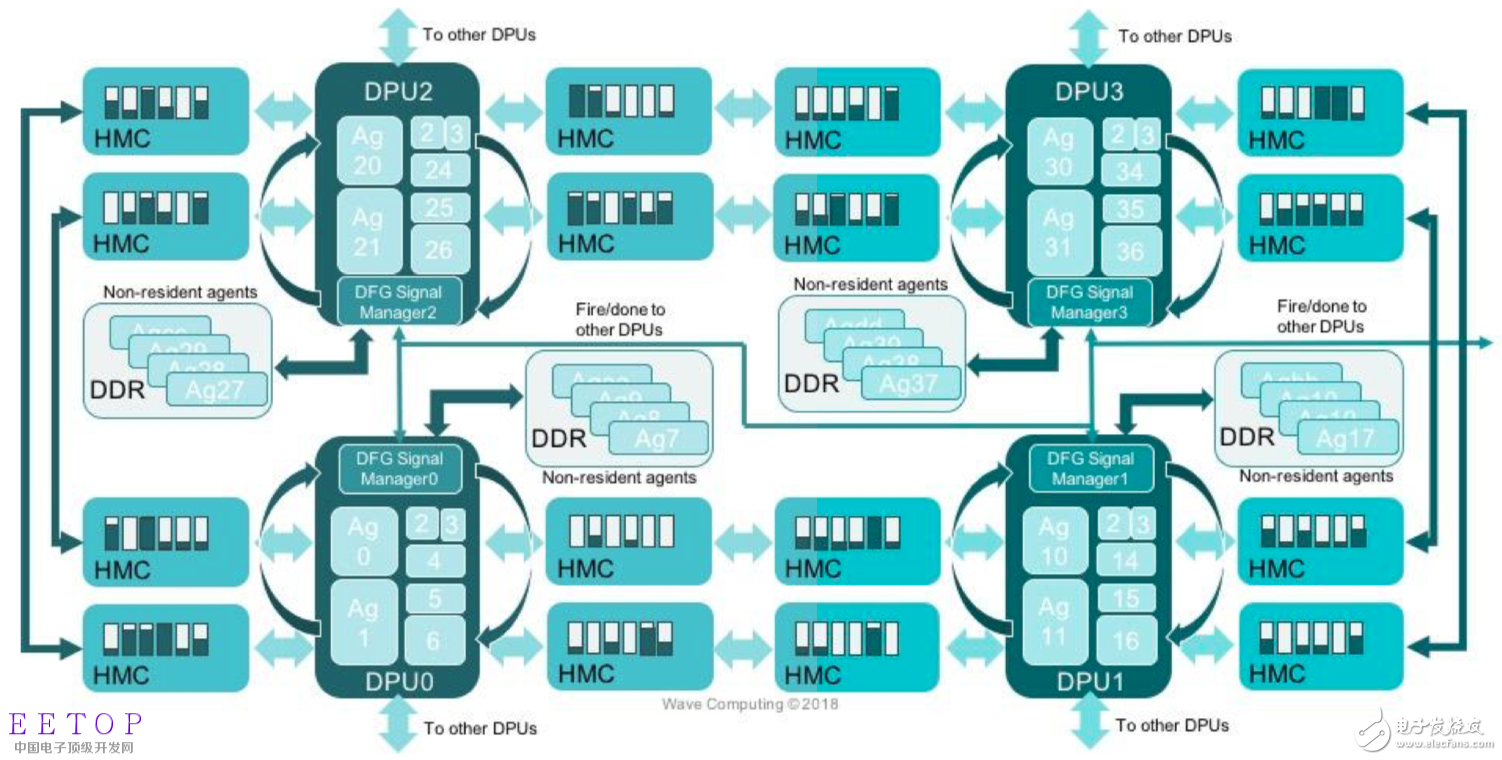
Figure 3: The first-generation data stream processing unit calculated by Wave
One of the best indicators of the heterogeneous future of machine learning and supporting silicon comes from Microsoft-this is a huge buyer of FPGAs, GPUs and other deep learning.
"Although throughput-oriented architectures, such as GPGPUs and batch-oriented NPUs, are popular in offline training and services, they are not very efficient for online, low-latency services of DNN models," May 2018 A paper published this month describes the Brainwave project, which is the latest version of Microsoft's high-efficiency FPGA in deepneuralnetworking (DNN).
Microsoft took the lead in widely using FPGAs as neural network inference accelerators for DNN inference in large-scale data centers. Steven Woo, Rambus's distinguished inventor and vice president of enterprise solutions technology, said the company is not using them as simple coprocessors, but "more flexible, first-class computing engines."
According to Microsoft, the Brainwave project can use the Intel Stratix10 FPGA pool to provide an effective performance of 39.5TFLOPS, and these FPGAs can be called by any CPU software on the shared network. The framework-independent system exports deep neural network models, converts them into microservices, and provides "real-time" inference for Bing search and other Azure services.
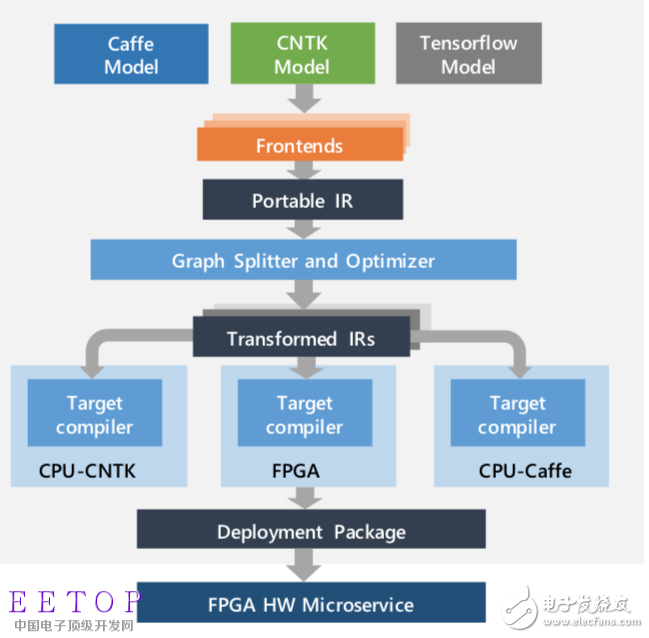
Figure 4: Microsoft's Brainwave project converts DNN models into deployable hardware microservices, exports any DNN framework as a general graphical representation, and assigns subgraphs to CPU or FPGA
Brainwave is part of what DeloitteGlobal calls a "dramatic shift" that will emphasize FPGAs and ASICs, which will account for 25% of the market share of machine learning accelerators by 2018. In 2016, CPUs and GPUs accounted for a market share of less than 200,000 units. Deloitte predicts that by 2018, CPUs and GPUs will continue to dominate, with sales exceeding 500,000 units, but as the number of ML projects doubles from 2017 to 2018, and doubles again from 2018 to 2020, The total market will include 200,000 FPGAs and 100,000 ASICs.
According to Deloitte, the power consumption of FPGAs and ASICs is much lower than that of GPUs and CPUs, and even lower than Google’s 75 watts of TPU per hour. They can also improve the performance of specific functions selected by the customer, which can change as the programming changes.
Steve Mensor, vice president of marketing at Achronix, said: "If people have their choice, they will build things with ASICs at the hardware level, but FPGAs have better power/performance than GPUs, and they are in fixed-point or variable-precision architecture. Very good at it."
Charlie Janac, Chairman and CEO of ArterisIP, said: "There are many, many memory subsystems. You have to consider low power consumption and IoT applications, grids and loops." "So you can put all of them on one chip. In, this is what you need to decide on IoT chips, or you can add a high-throughput HBM subsystem. But the workload is very special, each chip has multiple workloads. Therefore, the data input is huge, especially If you are dealing with things like radar and lidar, these things cannot exist without advanced interconnection.
Due to the particularity of the application, the type of processor or accelerator connected to the interconnection may vary greatly.
Anush Mohandass, vice president of marketing and business development at NetSpeedSystems, said: “In the core area, there is an urgent need to increase efficiency on a large scale.†“We can place ASICs and FPGAs as well as SoCs. More, we can put it in the rack. "But ultimately you must be efficient; you must be able to perform configurable or programmable multitasking. If you can apply multicast to vector processing workloads, and vector processing workloads are part of the training phase, then you What can be done will be greatly expanded."
FPGAs are not particularly easy to program, nor are they as easy to plug into designs as Lego bricks, although they are rapidly developing in this direction, SoCs are easier to use computing cores, DSP cores and other IP blocks than FPGAs.
However, the transition from SoC-like embedded FPGA chips to a complete system on a chip with a data backplane optimized for machine learning applications is not as easy as it sounds.
Mohandass said: "The performance environment is so extreme and the requirements are so different that the SoC in the AI ​​field is completely different from the traditional architecture." "Now there is more point-to-point communication. You are doing these vector processing tasks, and you are successful. Thousands of matrix rows, you have all these cores available, but we must be able to span hundreds of thousands of cores, not thousands.
Performance is crucial. The same is true for the ease of design, integration, reliability, and interoperability-SoC vendors focus on the underlying framework and design/development environment, not just chipsets for the specific needs of machine learning projects.
NetSpeed ​​has launched an updated version of the SoC integration platform specifically designed for deep learning and other artificial intelligence applications. This service makes it easier to integrate NetSpeedIP. The design platform uses a machine learning engine to recommend IP blocks to complete the design. The company said its goal is to provide bandwidth across the entire chip, rather than the centralized processing and memory of traditional designs.
Mohandass said: "Everything is in progress from ASICs to neuromorphic chips to quantum computing, but even if we don’t need to change the overall foundation of our current architecture (to accommodate new processors), the mass production of these chips is still Nowhere in sight." But we are all solving the same problem. When they work from top to bottom, we also work from bottom to top.
GeoffTate, CEO of FlexLogix, believes that CPU is still the most commonly used data processing element in data centers, followed by FPGA and GPU. But he pointed out that demand is unlikely to drop in a short period of time because data centers try to keep up with the demand for their own machine learning applications.
Tate said: "Now people spend a lot of money to design a better product than GPU and FPGA." "The general trend seems to be more specialized neural network hardware, so this is where we might go. "For example, Microsoft said that they use everything-CPU, GPU, TPU and FPGA-based on these, they can get the best price/performance ratio under a specific workload.
The so-called mini projector is also called pico projector, TRT-Lcos Portable Projector. Mainly through the 3M LCOS RGB three-color projector and 720P film decoding technology, the traditional huge projector is refined, portable, miniaturized, entertaining and practical, making the projection technology closer to life and entertainment.
Usually the projector has certain regulations on 2 aspects:
a). Size: Usually the size is the size of a mobile phone.
b). Battery life: It is required to have at least 1-2 hours or more of battery life when it is not connected to power.
In addition, its general weight will not exceed 0.2Kg, and some do not even need fan cooling or ultra-small silent fan cooling. It can be carried with you (it can be put into your pocket), and the screen can be projected to 40-50 inches or more.
Advantage:
1. Completely replace the MP5 player, video, listening to songs, playing games, e-books, picture browsing, etc. MP5 video is affected by physical performance, the screen can not be bigger, and the screen of this thing is at least 20 inches.
2. Instead of the TV function, the machine can have a built-in CMMB function, or it can be directly connected to the set-top box to play the TV, and it can be used as a 21-inch TV during the day.
Look, it can be used as a 60-100-inch TV at night to achieve the effect of home theater; it is convenient to move and break through the traditional film and television space. Even if you are on the mountain, you can also share today's TV series, movies, and MTV with your lover.
3. Business office: instead of large projectors, it is used for company meetings; the price of large projectors is 4,000 to 14,000, and the lamp life is more than 1,000 hours, which is not convenient to carry. 30,000 hours, no need to change the bulb for 3 years, easy to carry, the salesman only needs to bring a micro projector to demonstrate the new product, which can achieve the demonstration effect.
4. Teaching: training meetings, classroom teaching; traditional projectors are not easy to carry. In school classrooms, due to the naughty students, projectors are not safe to place in the classroom and are easily damaged by students. The portability of micro projectors makes up for the teaching vacancies. In the future, teachers only need to store the materials in the projector and show them to students for teaching, saving the trouble of textbooks and handwriting with pens and chalks.
In addition, the micro-projection has no radiation, which can fully protect pregnant women and people with myopia. Its low power consumption function is 1/1,000,000 of the power consumption of color TVs. One day of electricity has completely impacted the indicators of safety, environmental protection, health, etc., and has made amazing contributions to future social development, standing at the peak of the green world as a leader.
best mini projectors under £100,mini projector pvo portable projector,mini projector portable,mini projector amazon,mini projectors for movies
Shenzhen Happybate Trading Co.,LTD , https://www.szhappybateprojectors.com