The picture can only represent the momentary image of the thing, and the animation needs to be hand-drawn frame by frame, which is time-consuming and laborious. Can artificial intelligence help us solve this difficulty? Recently, researchers from York University and Ryerson University in Canada proposed an animation generation method using the "shuangliu convolutional neural network", which refers to the dual-path mode of human perception of dynamic texture images. The animation generation model can refer to related videos and make a static picture become a realistic animation. At present, the research paper has been accepted by the CVPR 2018 conference and related codes have also been published.

Animation generation effect display
Many common timing visual modes use the set of appearance and dynamics (that is, timing pattern changes) of the constituent elements to describe. Such patterns include fire, swaying trees and undulating water. For a long time, understanding and characterizing these timing patterns has been of interest in the fields of human perception, computer vision, and computer graphics. Previous studies have given names to these models, such as turbulent-flow motion [17], temporal texture [30], time-varying texture [3], dynamic texture [ 8], textured motion [45] and spacetime texture [7]. The author of this paper uses "dynamic texture". This study proposes factor analysis of dynamic textures from the perspective of appearance and timing dynamics. Then use a factorization result to complete the dynamic texture synthesis based on the sample texture input to generate a new dynamic texture instance. It also produces a new style of transition, where the target appearance and dynamics come from different sources, as shown in Figure 1.
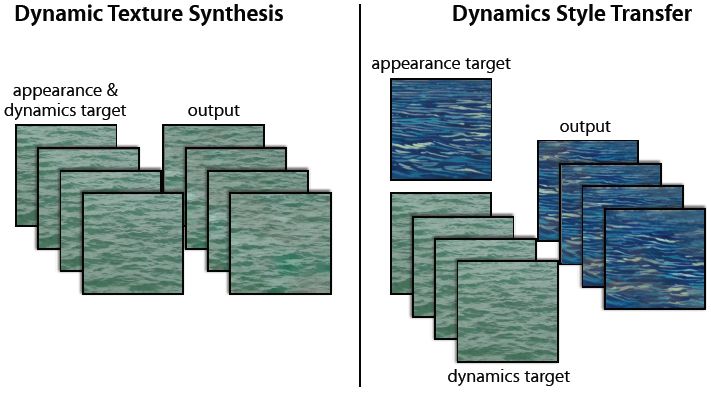
Figure 1: Dynamic Texture Synthesis. (Left) Given an input dynamic texture as a target, the dual stream model proposed in this paper can synthesize a new dynamic texture, retaining the appearance and dynamic characteristics of the target. (Right) The dual-stream model allows the synthesis to combine the texture appearance of one target with the dynamics of another target, resulting in a composite of the two.
The model proposed in this study consists of two convolutional networks (ConvNet)—the appearance flow and the dynamic flow. The two are pre-trained for target recognition and optical flow prediction. Similar to the spatial texture study [13, 19, 33], this paper summarizes the input dynamic texture based on the spatio-temporal data set of the filter output for each stream. The appearance flow modeled the appearance of the input texture each frame, and the dynamic flow modeling time series dynamics. The synthesis process includes optimizing randomly initialized noise patterns to match the spatiotemporal data of each stream with the spatiotemporal data of the input texture. The architecture is inspired by human perception and neuroscience. Specifically, the study of psychophysics [6] shows that humans can perceive the structure of dynamic textures, even when there are no appearance hints, indicating that the two streams are independent. Similarly, the dual-stream hypothesis [16] models the human visual cortex from two paths: ventral flow (responsible for target recognition) and dorsal flow (responsible for motion processing).
The dual-stream analysis of dynamic texture proposed in this paper is also applied to texture synthesis. The researchers considered a large number of dynamic textures and showed that their methods can generate new high-quality samples that match the frame-by-frame look and timing changes of the input samples. In addition, the appearance and dynamic factorization also produces a new style of style transition where the dynamics of one texture can be combined with the appearance of another texture. We can even use a single image as the appearance target to complete this operation, turning the static image into an animation. Finally, the researchers verified the realism of their texture generation through extensive user research.
Technical method
The dual-stream approach proposed in this paper includes an appearance flow (representing the static (texture) appearance of each frame) and a dynamic flow (representing the timing variation between frames). Each stream includes a convolutional neural network whose activation data is used to characterize dynamic textures. Synthesizing dynamic textures is an optimization problem that aims to match activation data. The dynamic texture synthesis method proposed in this paper is shown in Figure 2.
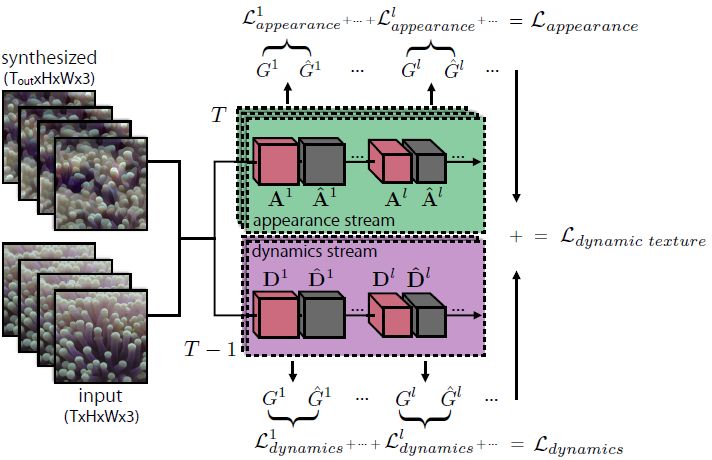
Figure 2: Dual stream dynamic texture generation. The Gram matrix set represents the appearance and dynamics of the texture. Matching this data enables the generation of new textures and the style transition between textures.
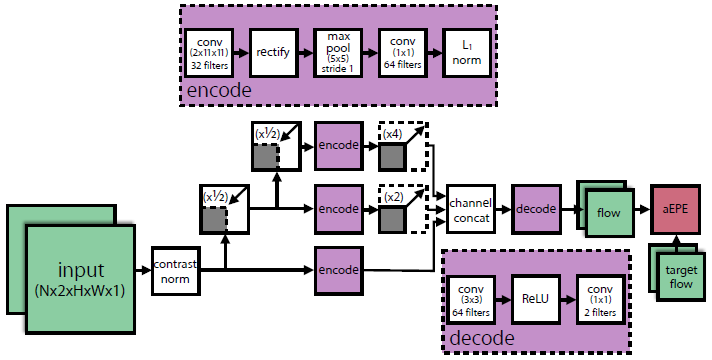
Figure 3: Dynamic flow convolutional neural network. The ConvNet is based on a space-time-oriented energy model [7, 39] and undergoes optical flow prediction training. The figure shows three scales. In practice, the researchers used five extensions.
Experimental results
(Dynamic) The goal of texture synthesis is to let the computer generate samples that human observers cannot distinguish whether they are real images. The study also showed a variety of synthetic results and a large number of user surveys to quantitatively assess the fidelity of the images generated by the new model. Due to the time-varying characteristics of the generated images, the results of this study are mostly video presentations. The researchers stated that the dual-stream architecture is implemented by TensorFlow and uses the NVIDIA Titan X (Pascal) GPU to generate the results. The image synthesis takes between 1 and 3 hours. Each time 12 frames are generated, the image resolution is 256×. 256.

Abstract: This paper presents a dual-flow model for dynamic texture synthesis. Our model is based on two pre-trained convolutional neural networks (ConvNet) for two separate tasks: target recognition, optical flow prediction. Given an input dynamic texture, the filter response data from the target recognition convolutional neural network compresses the appearance of each frame of the input texture, while the data from the optical flow convolutional neural network models the dynamics of the input texture. In order to generate a completely new texture, the random initialization input sequence is optimized to match the input texture data with the characteristic data of each stream. Inspired by recent image style migrations and benefiting from the dual-stream model presented in this article, we also attempted to synthesize the look of a texture and the dynamics of another texture to generate a completely new dynamic texture. Experiments show that our proposed method can generate new, high quality samples that match the frame-by-frame appearance of the input texture and its change over time. Finally, we conducted a quantitative user evaluation to evaluate the new texture synthesis method.
Description:
This mining rig has been designed from the ground up to keep GPUs cool with 5 powerful cooling fans.
You can install 8 GPUs at the same time without worrying about heat dissipation.
Its a stable machine thats incredibly easy to set up and requires little maintenance, making it an ideal rig for mass scaling.
Item Name: 8 GPU PC Case
Material: SECC
Color: Silver
Size: 750*400*179mm
Motherboard type: ATX/M-ATX/Mini ATX
Power supply: Support ATX PSU*1
Graphics card type: Support 9 33cm long graphics card
Number of graphics cards: 8 GPU
Number of fans: 4
Specifications:
Type: Vertical
Feature: With fan
Style: With Side Panel Window
Application: Server
Applicable graphics card: GPU P104,GPU P106,GPU 1660,GPU 3060,GPU 3070,GPU 3080,GPU 580,GPU 598, GPU 5600XT,GPU 5700XT
build mining rig,pre built mining rig,mining rig sale,prebuilt mining rig,mining rig frames
Easy Electronic Technology Co.,Ltd , https://www.pcelectronicgroup.com