Professor Zhou Ligong's years of hard work "Programming and Data Structure" and "Programming for AMetal Framework and Interface (I)", after the publication of the book content, set off a learning boom in the electronics industry. Authorized by Professor Zhou Ligong, this public number has serialized the contents of the book "Programming and Data Structure" and is willing to share it.
The third chapter is the algorithm and data structure. This article is a 3.3 doubly linked list.
> > > 3.3 Doubly linked list
To add or delete a singly linked list, you must find the previous node of the current node, so that you can modify the p_next pointer of the previous node to complete the corresponding operation. Since the node of the singly linked list does not have a pointer to its previous node, only the linked list is traversed from the head node. When a node's p_next points to the current node, it indicates that it is the previous node of the current node. Obviously, every time you have to traverse from the beginning, its efficiency is extremely low. In the singly linked list, the reason for directly obtaining the next node of the current node in the singly linked list is because the node contains a pointer p_next pointing to the next node. If you add a forward pointer p_prev to its previous node in the node of the doubly linked list, then all problems will be solved. Then, the linked list that points to both the next node and the pointer to the previous node is called a doubly linked list. See Figure 3.15 for details.

Figure 3.15 Schematic diagram of the doubly linked list
Like the singly linked list, the doubly linked list also defines a head node. Based on the design idea that the unidirectional linked list completely separates the application data from the linked list structure related data, the doubly linked list node only retains the p_next and p_prev pointers. Its data structure is defined as follows:

Where dlist is an abbreviation for double list, indicating that the node is a doubly linked list node. It can be seen that although the forward pointer makes it easy to find the last node of the linked list, because of the addition of a pointer in the node, its memory overhead will be twice that of the singly linked list. In practical applications, efficiency and memory space should be weighed. In the case where memory resources are very scarce, if the addition and deletion operations of nodes are rare and the effect of efficiency is acceptable, then the unidirectional linked list is selected. Rather than blindly pursuing efficiency, the two-way linked list is better than the one-way linked list, and always chooses to use a doubly linked list.
In Figure 3.15, the p_prev of the head node and the p_next of the tail node are directly set to NULL. In this case, if the tail node is to be found directly by the head node, or the head node is found by the tail node, the entire node must be traversed. Linked list. You can use these two pointers slightly, so that the head node's p_prev points to the tail node, and the tail node's p_next points to the head node. At this point, the doubly linked list becomes a circular doubly linked list. See Figure 3.16 for details. .
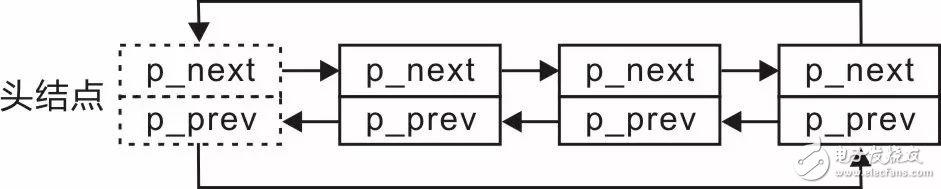
Figure 3.16 Schematic diagram of the circular doubly linked list
Because the circular doubly linked list is more efficient, you can find the tail node directly from the head node, or find the head node from the tail node, and there is no extra memory space consumption, just use two pointers that are not intended to be used. Waste utilization, so the doubly linked list described below is considered a circular doubly linked list.
Similar to a singly linked list, although the head node is exactly the same as the normal node, their meanings are different. The head node is the head of the linked list, which represents the entire linked list. Has the entire list. In order to distinguish between the head node and the normal node, a head node type can be defined separately. such as:
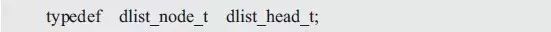
When you need to use a doubly linked list, you first need to define a header node with this type. such as:

Since no other nodes have been added at this time, there is only one head node, so the head node is both the first node (head node) and the last node (tail node). According to the definition of the circular linked list, the p_next of the tail node points to the head node, and the p_prev of the head node points to the tail node. The schematic diagram of only one node is shown in Figure 3.17.
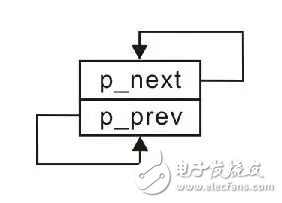
Figure 3.17 Empty linked list
Obviously, when there are only head nodes, both p_next and p_prev point to themselves. which is:

In order to prevent users from directly manipulating members, you need to define an initialization function that is used to initialize the values ​​of each member of the linked list header. The function prototype (dlist.h) is:

Among them, p_head points to the link header node to be initialized. The form of its call is as follows:

The implementation of the dlist_init() function is detailed in Listing 3.33.
Listing 3.33 Doubly linked list initialization function

Similar to a singly linked list, it will provide some basic operational interfaces. Their function prototypes are as follows:

For dlist_prev_get() and dlist_next_get(), there are already pointers to the predecessor in the linked list node, as shown in Listing 3.34.
Listing 3.34 shows the implementation of the node predecessor and subsequent functions.

The dlist_tail_get() function is used to get the tail node of the linked list. In the circular doubly linked list, the p_reev of the head node points to the tail node. See Listing 3.35 for details.
Listing 3.35 dlist_tail_get() function implementation

The dlist_begin_get() function is used to get the first user node, as shown in Listing 3.36.
Listing 3.36 dlist_begin_get() function implementation

Dlist_end_get() is used to get the end position of the linked list. When the doubly linked list is designed as a circular doubly linked list, the p_prev of the head node and the p_next of the tail node are effectively utilized, and neither p_next nor p_prev of any valid node Then NULL. Obviously, NULL can no longer be used as the end position. When the nodes of the linked list are sequentially accessed from the first node, the next node of the tail node is the head of the list, so the end position is the head. The node itself. The implementation of dlist_end_get() is detailed in Listing 3.37.
Listing 3.37 dlist_end_get() function implementation

3.3.1 Adding Nodes
Assuming that the node is still added to the end of the list, the function prototype is:

Among them, p_head is a pointer to the node of the list header, p_node is a pointer to the node to be added, and its usage example is shown in Listing 3.38.
Listing 3.38 dlist_add_tail() function example

In order to implement this function, you can first check the changes of the linked list before and after adding the node, as shown in Figure 3.18.
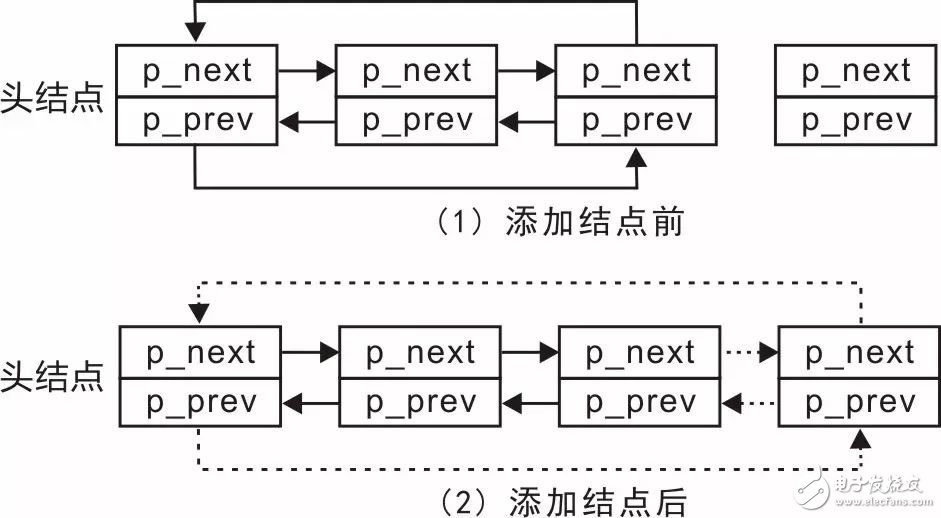
Figure 3.18 Adding a node diagram
Thus, adding a node to the end of the list requires 4 pointers (dashed arrows in the figure):
The new node's p_prev points to the tail node;
The new node's p_next points to the head node;
The p_next of the tail node changes from pointing to the head node to pointing to the new node;
The p_prev of the head node is modified from pointing to the tail node to point to the new node.
After these operations, when the node is added to the end of the list, it becomes a new tail node. See Listing 3.39 for details.
Listing 3.39 dlist_add_tail() function implementation

In fact, the circular list, whether it is a head node, a tail node or a normal node, is essentially the same, with the p_next member pointing to the next node and the p_prev member pointing to the previous node. Therefore, for adding nodes, whether the nodes are added to the list header, the end of the chain, or any other location, the operation method is exactly the same. To do this, you need to provide a more general function, you can add nodes to any node, the function prototype is:
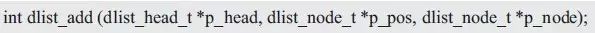
Where p_head is a pointer to the node of the list header, p_pos specifies the location to be added, the new node is added after the node pointed to by the pointer; p_node is a pointer to the node to be added. For example, the same node is added to the end of the list. For an example of its use, see Listing 3.40.
Listing 3.40 dlist_add() function example

It can be seen that the position where the tail node is added as a node can also be added to the tail of the linked list after the node is added to the tail node. Obviously, there is no need to write the dlist_add_tail() implementation code. Use dlisd_add() to modify the implementation of the dlist_add_tail() function. See Listing 3.41 for details.
Listing 3.41 dlist_add_tail() function implementation

In order to implement the dlist_add() function, you can first check the situation after adding a node to any node, as shown in Figure 3.19. The figure shows a general case. Since the addition position (head, tail or any other position) of the node has nothing to do with the method of adding the node, the head node and the tail node are not specifically marked.

Figure 3.19 Schematic diagram of adding a node
In fact, comparing Figure 3.18 with Figure 3.19, it can be found that Figure 3.18 shows only a special case of Figure 3.19, that is, the node before the new node in Figure 3.19 is the tail node. The process of adding nodes also needs to be modified. The value of the pointer. For convenience of description, the node before the new node is called the former node, and the node after the new node is called the back node. Obviously, before adding a new node, the next node of the previous node is the back node. The description of setting 4 pointer values ​​is as follows:
The new node's p_prev points to the previous node;
The new node's p_next points to the last node;
The p_next of the previous node changes from pointing to the next node to pointing to the new node;
The p_prev of the post node is modified by pointing to the previous node to point to the new node.
To compare the description of adding a node to the end of the list, just replace the "predecessor" in the description with the "tail node" and the "post node" with the "head node". Their meanings are exactly the same, obviously Adding a node to the end of the list is just a special case. The function implementation for adding a node is detailed in Listing 3.42.
Listing 3.42 dlist_add() function implementation

Although the above function does not use the parameter p_head when it is implemented, the p_head parameter is passed in, because the p_head parameter will be used to implement other functions, for example, to determine whether p_pos is in the linked list.
With this function, adding a node to any position is very flexible. For example, provide a function that adds a node to the head of the linked list as the first node of the linked list. The function prototype is:
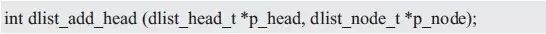
At this point, the head node is the front node of the newly added node, which can be directly implemented by calling dlist_add(). For the implementation example, see Listing 3.43.
Listing 3.43 dlist_add_head() function implementation

3.3.2 Deleting Nodes
Based on the idea of ​​adding nodes to arbitrary locations, you need to implement a function that removes any nodes. Its function prototype is:

Among them, p_head is a pointer to the node of the list header, and p_node is a pointer to the node to be deleted. For details, see Listing 3.44.
Listing 3.44 dlist_del() uses the sample program

In order to implement the drisd_del() function, you can first view the schematic diagram of deleting any node. Figure 3.20(1) is the schematic diagram before deleting the node, and Figure 3.20(2) is the schematic diagram after deleting the node.
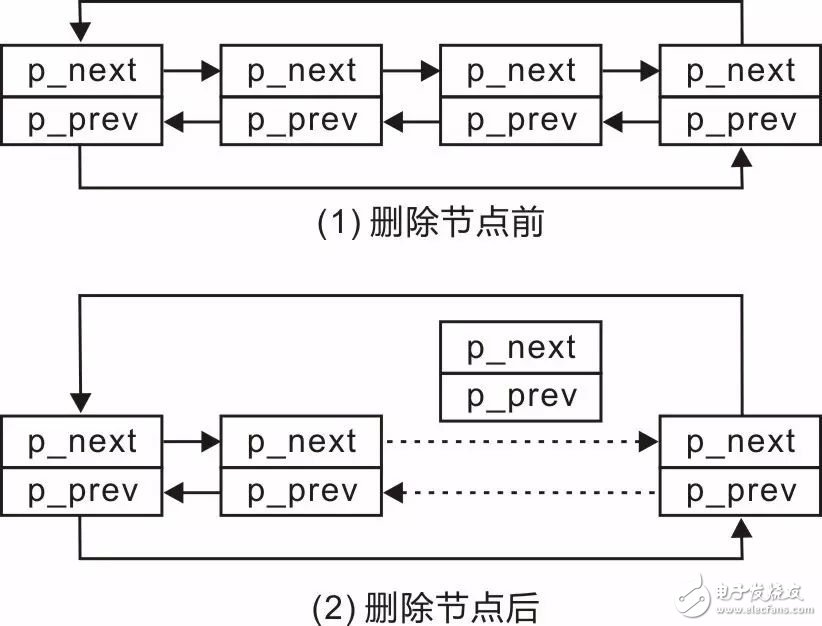
Figure 3.20 Adding a node diagram
Thus, you only need to modify the values ​​of the two pointers:
Modify the p_next of the previous node of the "Delete Node" to point to the post node of the "Delete Node";
Modify the p_prev of the post node of the "Delete Node" to point to the previous node of the "Delete Node".
The implementation of the delete node function is detailed in Listing 3.45.
Listing 3.45 dlist_del() function implementation

In order to prevent the deletion of the head node, p_head and p_node are compared in the program. When p_node is the head node, the error is directly returned.
3.3.3 Traversing the linked list
Similar to a singly linked list, you need a function that traverses each node of the linked list. The function prototype (dlist.h) is:

Among them, p_head points to the link header node, pfn_node_process is the node processing callback function, and each function is called when it is traversed to a node, which is convenient for the user to process the node. The dlist_node_process_t type is defined as follows:

The dlist_node_process_t type parameter is a p_arg pointer and a node pointer, and the return value is a function pointer of type int. Each time a node is traversed, the function pointed to by pfn_node_process is called, which is convenient for the user to process the node data as needed. When the callback function is called, the value passed to p_arg is the user parameter, and its value is the same as the third parameter of the dlist_traverse() function, that is, the value of the parameter is completely determined by the user; the value passed to p_node is Pointer to the node that is currently traversed. When traversing to a node, if the user wishes to terminate the traversal, at this point, simply return a negative value in the callback function to terminate the traversal. In general, if you want to continue traversing, you can return 0 after the execution of the function. The implementation of the dlist_foreach() function is detailed in Listing 3.46.
Listing 3.46 Implementation of the linked list traversal function

For ease of reference, the contents of the dlist.h file are shown as shown in Listing 3.47.
Listing 3.27 Contents of the dlist.h file

The int type data is also taken as an example to show how to use these interfaces. In order to use a linked list, you should first define a structure, with the linked list node as a member. In addition, add some application-related data, such as a structure with the following linked list nodes and int data:

The integrated sample procedure is detailed in Listing 3.48.
Listing 3.48 Integrated Sample Program

Comparing with the comprehensive example program of the singly linked list, it can be found that the main body of the program is exactly the same, only the type of each node has changed. For practical applications, if you upgrade to a doubly linked list by using a singly linked list, although the program body has not changed, due to the type change, you have to modify all the program code. This is because the application is not separated from the specific data structure, so the actual application can be further separated from the specific data structure, and the data structure such as the linked list is abstracted into the concept of "container".
Wireless Barcode Scanner,Bluetooth Barcode Scanner,Wifi Barcode Scanner,Portable Barcode Scanner
ShengXiaoBang(GZ) Material Union Technology Co.Ltd , https://www.sxbgz.com