Editor's note: Semi-supervised learning is a very popular research field in recent years. After all, the essence of machine learning model is a "monster" that "eats" data. Although the real world has massive data, the labeled data for a certain problem is still extremely high. Scarce. In order to accomplish more real-world tasks with less labeled data, researchers came up with this ingenious method of extracting data structures from unlabeled data. So can it be used for real-world tasks? Today Lunzhi brought a Google Brain paper included in NIPS 2018: Realistic Evaluation of Semi-Supervised Learning Algorithms.

Summary
Semi-supervised learning (SSL) provides a powerful framework when encountering problems such as limited labeling or insufficient funds to invite people to label data. In recent years, SSL algorithms based on deep neural networks have proven useful in standard benchmarking tasks. However, we believe that these benchmarks cannot solve the various problems that these algorithms will face when applied to actual tasks.
We recreated unified implementations for some widely used SSL algorithms and tested them in a series of tasks. Experiments have found that: the performance of simple baselines that do not use unlabeled data is usually underestimated; for different amounts of labeled data and unlabeled data, the sensitivity of the SSL algorithm is also different; and when the unlabeled data set contains those that do not belong to this category When data, network performance will be greatly reduced.
In order to help guide SSL research to truly adapt to the real world, we have published a unified re-implementation and evaluation platform for the paper.
Introduction
Numerous experiments have confirmed that if we label a large amount of data, then deep neural networks can achieve similar or even superhuman performance on some supervised learning tasks. However, this success comes at a price. In other words, in order to create a large data set, we often have to expend a lot of manpower, financial resources, and risk on data labeling. Therefore, for many practical problems, they do not have enough resources to construct a large enough data set, which limits the wide application of deep learning.
One possible way to solve this problem is to use a semi-supervised learning framework. Compared with supervised learning algorithms that require labeled data, the SSL algorithm can extract data structures from unlabeled data, thereby improving network performance, which lowers the operating threshold. And some recent research results also show that, in some cases, even if most of the data in a given data set has lost labels, the SSL algorithm can approach the performance of purely supervised learning.
In the face of these successes, a natural question is: Can SSL algorithms be used for real-world tasks? In this article, we believe that the answer is no. Specifically, when we select a large data set and then remove a large number of labels from it to compare the SSL algorithm and the purely supervised learning algorithm, we actually ignore the various common features of the algorithm itself.
Here are some of our findings:
If two neural networks spend the same resources on tuning parameters, the performance difference between using SSL and using only labeled data will be smaller than the experimental conclusions of previous papers.
Large, highly regularized classifiers that do not use unlabeled data tend to have strong performance, which proves the importance of evaluating different SSL algorithms on the same underlying model.
If you pre-train the model on different labeled data sets, and then train the model on the specified data set, its final performance will be much higher than using the SSL algorithm.
If the unlabeled data contains a different class distribution from the labeled data, the performance of the neural network using the SSL algorithm will drop sharply.
In fact, a small validation set prevents reliable comparisons between different methods, models, and hyperparameter settings.
Evaluation method improvement
Researchers generally follow the following process to evaluate SSL algorithms: First, select a general data set for supervised learning, delete most of the data labels; second, make the data with reserved labels into a small data set D, and put the unlabeled data Organize into a data set DUL; finally, use semi-supervised learning to train some models, and test their performance on the unmodified test set.
But the following are the shortcomings and improvements of the existing methods:
P.1 A shared implementation
The existing SSL algorithm does not consider the consistency of the underlying model, which is unscientific. In some cases, it is also a simple 13-layer CNN, and different implementations will lead to changes in some details, such as parameter initialization, data preprocessing, data enhancement, and regularization. The training process (optimization, several epochs, learning rate) of different models is also different. Therefore, if the same underlying implementation is not used, the algorithm comparison is not rigorous enough.
P.2 High-quality supervised learning baseline
The goal of SSL is based on the labeled data set D and the unlabeled data set DUL, so that the performance of the model is better than the identical basic model trained with D alone. Although the reason is simple, there are differences in the introduction of this baseline in different papers. For example, last year, Laine & Aila and Tarvainen & Valpola used the same baseline in the paper. Although the models are the same, their accuracy difference is as high as 15%.
In order to avoid this situation, we refer to SSL tuning and re-adjust the baseline model to ensure its high quality.
P.3 Comparison with transfer learning
In practice, if the amount of data is limited, we usually use transfer learning to take the model trained on a similar large data set, and then "fine-tune" based on the small data set at hand. Although the premise of this approach is that there is a similar and large enough data set, if it can be implemented, transfer learning can indeed provide a powerful and versatile baseline, and this type of baseline is rarely mentioned in papers.
P.4 Consider the mismatch of class distribution
It should be noted that when we select the data set and delete the labels of most of the data, these data default to DUL's class distribution and D's exactly the same. But this is unreasonable. Imagine that we want to train a classifier that can distinguish ten faces, but the image samples of each person are very small. At this time, you may choose to use a large unlabeled image containing random face images The data set is used for filling, then the image in this DUL is not exactly the ten people.
Existing SSL algorithm evaluations have ignored this situation, and we have explicitly studied the impact of data with the same class distribution/different class distributions.
P.5 Change the number of marked and unmarked data
It is not uncommon to change the number of two types of data. Researchers usually like to change the size of D by deleting different amounts of underlying label data. But so far, it is not common to change DUL in a systematic way. This can simulate two real-life scenarios: one is that the unlabeled data set is very huge (such as using billions of unlabeled images on the network to improve the classification performance of the model), and the other is that the unlabeled data set is relatively small (such as medical image data, their cost Very high).
P.6 Practical small validation set
The artificially created SSL data set often has a feature that the verification set is much larger than the training set. For example, the validation set of SVHN has about 7,000 labeled data. When many papers use this data set for research, they often only extract 1,000 labeled data from the original training set, but retain the complete validation set. This means that the validation set is 7 times the training set, and in real tasks, the set with more data will generally be used as the training set.
experiment
The purpose of this experiment is not to produce state-of-art results, but to conduct a rigorous comparative analysis of the performance of various models by establishing a general framework. In addition, because the model architecture and hyperparameter adjustment methods we use are very different from previous papers, they cannot be directly compared with past work, and can only be listed separately.
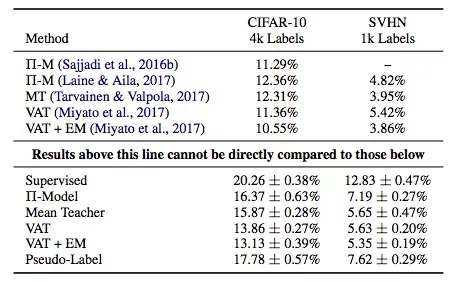
The above table is the error rate of the model of the practical SSL algorithm on the verification set. They use the same underlying model-Wide ResNet. The ordinate is the supervised learning and various commonly used SSL algorithms: Î -Model, Mean Teacher, Virtual Adversarial Training, PseudoLabeling, and Entropy Minimization.
It should be noted that the upper part of the table is the work of predecessors, and the lower part is the result of this article. They cannot be directly compared (the parameters used in the model in this article are half of the above, so the performance will be worse). However, through the data we can still find:
Conclusion 1: Mean Teacher and VAT performed well overall.
Conclusion 2: The performance difference between supervised learning model and semi-supervised learning model is not as large as described in other papers.
Conclusion 3: Based on the data in this table, we trained a model with transfer learning and found that its error rate on the CIFAR-10 validation set is 12%, which is better than the SSL algorithm.
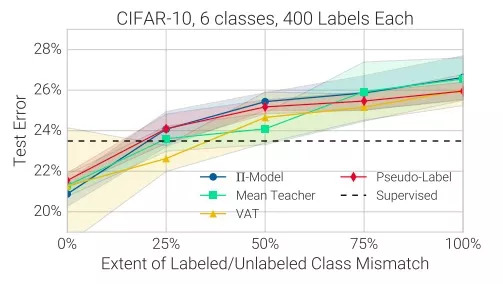
The above figure is the error rate of each model on CIFAR-10. It is known that the labeled training set has 6 types of images, and each type of image has 400 samples. The ordinate is the error rate, and the abscissa is the proportion of different types of unlabeled data relative to the distribution of labeled data. For example, 25% means that 1/4 of the classes in the unlabeled data set are not on the labeled data set. The shaded area is the standard deviation of the five experiments.
Conclusion 4: Compared with not using any unlabeled data, if we add more additional classes to the unlabeled data set, the performance of the model will decrease.
Conclusion 5: SSL algorithm is very sensitive to the different data volume of marked data/unmarked data.
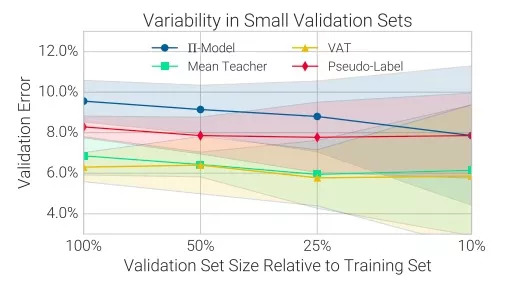
The above figure is a comparison of the average verification error of each algorithm model, using 10 random sampling non-overlapping verification sets of different sizes. The solid line is the average, the shading is the standard deviation, and the training set is the SVHN containing 1000 labeled data. The ordinate in the figure is the error rate, and the abscissa is the size of the validation set relative to the training set. For example, 10% means that the validation set only contains 100 labeled data.
Conclusion 6: 10% is an appropriate ratio. Therefore, for SSL algorithms that rely heavily on large verification sets for hyperparameter adjustments, their practical applicability is very limited, and even cross-validation cannot bring much improvement.
to sum up
Through the above experimental results, we have confirmed that the use of SSL algorithms in real practice is temporarily inappropriate, so how should we evaluate them in the future? Here are some suggestions:
When comparing different SSL algorithms, use exactly the same underlying model. Differences in the structure of the model, and even the details, will have a great impact on the final result.
Carefully adjust the accuracy of the baseline when using supervised learning and transfer learning. The goal of SSL should be significantly better than fully supervised learning.
The performance of the model changes when the presentation data is mixed with other types of data, because this is a very common phenomenon in real scenes.
When reporting performance, test the situation under different labeled data/unlabeled data volumes. Ideally, even if the labeled data is very small, the SSL algorithm can extract useful information from the unlabeled data. Therefore, we suggest combining SVHN and SVHN-Extra to test the performance of the algorithm in large unlabeled data.
Don't over-tune parameters on unrealistically large validation sets.
Our company specializes in the production and sales of all kinds of terminals, copper terminals, nose wire ears, cold pressed terminals, copper joints, but also according to customer requirements for customization and production, our raw materials are produced and sold by ourselves, we have their own raw materials processing plant, high purity T2 copper, quality and quantity, come to me to order it!
LYF Copper Lube Terminals,Ring insulated terminals
Taixing Longyi Terminals Co.,Ltd. , https://www.longyiterminals.com